Obsah
Jedním z hlavních cílů PDT 2.0 (viz sekce 1.1 - "Co je PDT 2.0") je poskytnout lingvistům velké množství skutečně reálných příkladů (nejen) jevů dříve popsaných v řadě teoretických prací zabývajících se závislostí, tektogramatickým popisem a přístupem funkčně-generativního popisu obecně. Využití takového korpusu by však bylo jen omezené, kdyby nebyl doplněn pohodlným nástrojem pro prohledávání.
Existuje přirozeně řada způsobů, jak korpus prohledávat. Velmi pokročilé vyhledávání umožňuje například nástroj btred/ntred, vyžaduje však jistou programátorskou dovednost (konkrétně znalost jazyka Perl a rozhraní btred/ntredu). Většině "běžných" uživatelů doporučujeme Netgraph, nástroj navržený a vytvořený právě pro snadné prohledávání PDT 1.0 a PDT 2.0.
Netgraph je aplikace typu klient-server, která umožňuje prohledávat PDT 2.0 současně několika uživateli, připojenými přes internet. Netgraph je navržený tak, aby prohledávání bylo co nejjednodušší a intuitivní, při zachování vysoké síly dotazovacího jazyka.
Komunikace mezi dvěma částmi Netgraphu, klientem a serverem, probíhá přes internet. Server prohledává korpus, který je umístěn na stejném počítači či lokální síti jako server. Klient slouží jako grafické rozhraní pro uživatele a může být umístěn kdekoliv na internetu. Posílá serveru dotazy a přijímá zpátky výsledky. Server a klient mohou být samozřejmě umístěny i na jednom počítači.
Netgraph server je napsán v C a C++ a běží v operačním systému Linux, dalších systémech unixového typu a na Apple Mac OS. Existuje i experimentální verze pro MS Windows. Umožňuje nastavit uživatelská konta s různými přístupovými právy. Korpus, určený k prohledávání Netgraphem, musí být ve formátu FS a v kódování UTF-8.
Netgraph klient je napsán v Javě a je nezávislý na platformě. Existuje ve dvou formách. První formou je samostatná javovská aplikace. V této podobě jsou dostupné všechny funkce klienta; musí však být nejprve nainstalován, spolu s Java 2 Runtime Environment. Druhou formou je javovský aplet. Ten, ač ochuzen o některé funkce, poskytuje plnou vyhledávací sílu a běží ve webovském prohlížeči bez předchozí instalace; vyžaduje ovšem, abyste měli ve svém prohlížeči nainstalovaný Java 2 plug-in.
Dotaz v Netgraphu je jeden uzel nebo strom s uživatelem definovanými vlastnostmi, který má být vyhledán v korpusu. Prohledání korpusu pak znamená hledat věty (samozřejmě ve formě anotovaných stromů), které obsahují dotaz jako svůj podstrom. Uživatel má možnost zadat dotazy nejrůznější složitosti, od těch nejjednodušších (jako je hledání všech stromů korpusu, které obsahují dané slovo), po velmi pokročilé (jako např. hledání všech vět, obsahujících sloveso rozvinuté adresátem, který není ve třetím pádě, a nejméně jedním příslovcem udávajícím směr, atd.). Dotazy mohou být dále rozšířeny tzv. meta atributy, které umožňují vyhledávat ještě složitější konstrukce. Meta atributy umožňují nastavení tranzitivních hran, volitelných uzlů, určení pozice dotazu v nalezených stromech, omezení velikosti nalezených stromů, nastavení pořadí uzlů, určení vztahů mezi hodnotami atributů u různých uzlů v nalezených stromech, negaci a mnoho dalších podmínek.
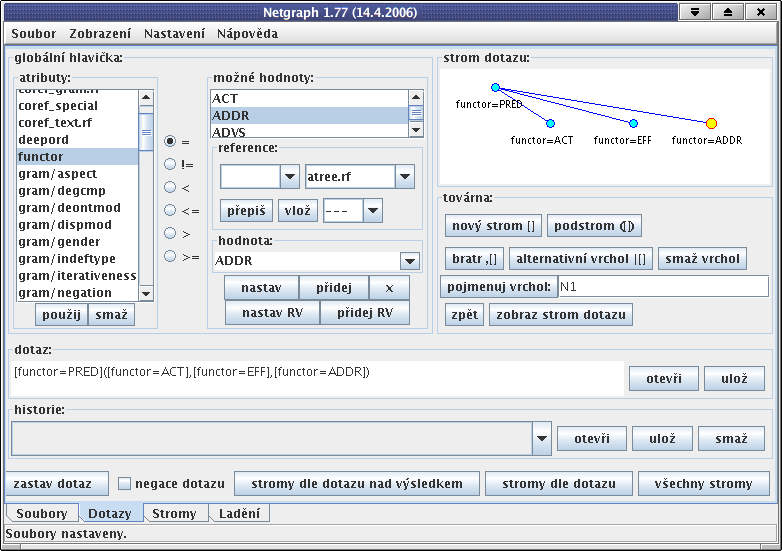
Dotazy se v Netgraphu vytvářejí v uživatelsky přívětivém grafickém prostředí. Příkladem je dotaz na obrázku 4.1 - "Vytváření dotazu v Netgraphu". V tomto jednoduchém dotazu hledáme všechny stromy, které obsahují uzel označený jako predikát, rozvitý nejméně třemi uzly, označenými jako aktor, efekt a adresát. Pořadí těchto uzlů v nalezených stromech není v dotazu nijak omezeno.
Jedním z výsledků, zaslaných zpět serverem, může být strom z obrázku 4.2 - "Nalezený strom v Netgraphu".
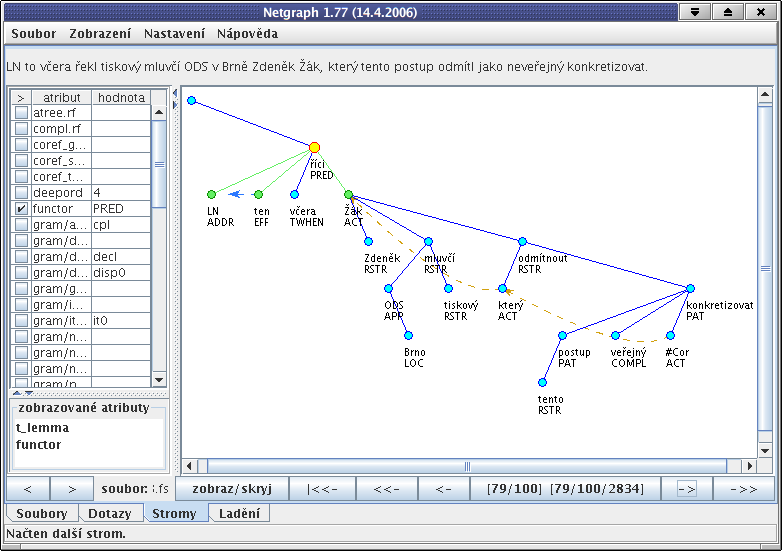
Uzly výsledného stromu, které odpovídají uzlům dotazu, jsou zvýrazněny žlutou a zelenou barvou. Všimněte si, že predikát ve výsledném stromě má více synů, než jsme určili v dotazu. To je v souladu s definicí vyhledávání v Netgraphu - stačí, že strom dotazu je v nalezeném stromě obsažen jako podstrom. Všimněte si dále, že pořadí uzlů v dotazu a ve výsledku jsou odlišná. Meta atributy umožňují omezit jak skutečný počet synů uzlu ve výsledném stromě, tak i výsledné pořadí uzlů, pokud si tak uživatel přeje.
Informace o způsobu instalace Netgraphu najdete v instrukcích k rychlé instalaci Netgraph klienta a v instrukcích k rychlé instalaci Netgraph serveru. Důležité informace najdete též v Manuálu k Netgraph klientu a v Manuálu k instalaci Netgraph serveru.
Poznamenejme, že instalovat Netgraph server potřebujete pouze v případě, že chcete prohledávat svůj vlastní korpus. Pro prohledávání PDT 2.0 poskytuje Ústav formální a aplikované lingvistiky výkonný server na adrese quest.ms.mff.cuni.cz a portu 2200. Je přístupný přes internet pro anonymního uživatele anonymous a připojit se k němu můžete pomocí Netgraph klienta (viz instrukce k rychlé instalaci Netgraph klienta).
Více informací o Netgraphu najdete v Manuálu k Netgraph klientu. Máte-li zájem o plný neanonymní přístup k serveru či máte-li zájem o další informace, aktualizace a novinky, navštivte domovskou stránku Netgraphu.
Nejpřehlednější a nejpohodlnější zobrazení dat PDT 2.0 poskytuje TrEd. Prvotně sloužil jako hlavní anotační nástroj, ale může být použit i k prohlížení dat a obsahuje také několik druhů vyhledávacích funkcí. Instrukce k instalaci TrEdu najdete v dokumentaci k TrEdu.
Pro otevření souborů v TrEdu zvolte menu a klikněte na položku . Vyberte jakýkoliv soubor *.t.gz (tj. soubor s tektogramatickou anotací nějakého dokumentu), TrEd jej otevře a ihned zobrazí strom pro první větu daného souboru.
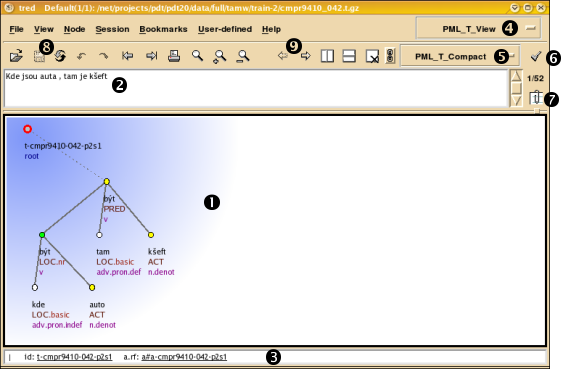
Typický vzhled TrEdu vidíte na obrázku 4.3 - "Tektogramatický strom v TrEdu"; jde o větu Kde jsou auta, tam je kšeft.
-
Na tomto místě vidíte jedno či více oken. Každé okno zobrazuje jeden strom.
-
V tomto poli vidíte prostou textovou formu věty zobrazené v právě vybraném okně.
-
Stavová řádka. Zobrazuje různé informace v závislosti na aktuálním kontextu.
-
Aktuální kontext. Kontext můžete změnit kliknutím na jméno aktuálního kontextu a následným výběrem nového kontextu ze zobrazeného seznamu (např.
PML_T_Edit). -
Aktuální zobrazovací styl. Může být změněn podobným způsobem jako kontext.
-
Sem klikněte pro editaci zobrazovacího stylu.
-
Kliknutím sem zobrazíte seznam všech vět aktuálního souboru. Nad tlačítkem je zobrazeno pořadí aktuálního stromu v aktuálním souboru.
-
Tlačítka pro otevření, uložení a opětovné otevření souboru. Ikony znamenají Undo, Redo, Previous a Next File, Print, Find, Find Next, Find Previous.
-
Tlačítka pro přesunutí na předchozí/následující strom v aktuálním souboru a pro správu oken.
Implicitně jsou tektogramatické soubory PDT 2.0 v PML formátu otevřeny v kontextu PML_T_View, který neumožňuje jejich editaci. Pokud si přejete soubory měnit, přepněte se do kontextu PML_T_Edit. V obou kontextech jsou k dispozici dva zobrazovací styly. Implicitní je PML_T_Compact, pro zobrazení více podrobností můžete použít PML_T_Full. Informace o kontextech a zobrazovacích stylech najdete v dokumentaci k makrům v TrEdu.
V libovolném kontextu můžete zobrazit seznam všech maker definovaných v daném kontextu a jejich klávesové zkratky, a to vybráním menu ->.
Netgraph (popsaný v sekci 4.1 - "Vyhledávání v korpusu: Netgraph") umožňuje i neprogramátorům snadno a pohodlně vyhledávat stromy v PDT. Editor TrEd (popsaný v sekci 4.2 - "Prohlížení stromů: TrEd") umožňuje rychlé, pohodlné a flexibilní procházení, prohlížení a úpravu jednotlivých stromů. Vývojáři nástrojů a programátoři obecně však potřebují plný přístup k datům. Můžete samozřejmě data zpracovávat přímo (koneckonců, jsou v XML), my ale doporučujeme k datům přistupovat pomocí perlovského rozhraní btred/ntred, ušitého datům PDT 2.0 na míru. btred je perlovský program, který umožňuje aplikaci jiného perlovského programu (zvaného makro btredu) na data uložená v jednom z formátů PDT. ntred je btred ve verzi klient-server a je vhodný pro paralelní zpracování dat na více strojích. (Mnemotechnika pro btred/ntred: "b" znamená "batch processing", dávkové zpracování, "n" znamená "networked processing", zpracování po síti.)
Budete-li postupovat podle uvedeného doporučení, získáte několik výhod:
- Objektově orientovaná reprezentace stromů, použitá v prostředí
btred/ntredu, nabízí velké množství základních funkcí pro procházení stromů a pro mnoho dalších základních operací na stromech; k dispozici je i několik značně pokročilých funkcí, vhodných pro lingvisticky motivované procházení stromů (funkce, které berou v úvahu například vzájemné propojení mezi relacemi závislosti a koordinace). - Technologie
btred/ntredubyla široce používána několika programátory během vývoje PDT 2.0; tato dlouhodobá zkušenost vedla k mnoha vylepšením, díky nimž jsou tyto nástroje a přidružené knihovny rozumně stabilní. - Máte-li k dispozici více počítačů, můžete použít
ntreda zpracovávat data paralelně, což výpočet výrazně zrychluje. V závislosti na konkrétní situaci může být průchod celým PDT 2.0 zkrácen na pouhých několik sekund (s pouze přibližně 10 procesory přístupnými pro distribuovaný běhbtredu). - Programátoři mohou
btred/ntred(v kombinaci sTrEdem) použít jako mocný a rychlý vyhledávací stroj. Napíšete makro, které v korpusu vyhledá pozice, o které se zajímáte, spustíte ho vntredua získané pozice si jednoduše prohlédnete vTrEdu. - K tomu, abyste si osvojili psaní maker pro
btred/ntred, potřebujete jen znát základy syntaxe jazyka Perl a zapamatovat si jména několika proměnných a funkcí, předdefinovaných v prostředíbtred/ntredu. - Jakmile si na práci s
btred/ntredemzvyknete, budete moci všech jeho výhod využít i při zpracování dat dalších korpusů (ať už závislostních, nebo i bezprostředně složkových).
Pro úvodní seznámení si přečtěte tutoriál k btred/ntredu. Podívejte se také na manuálové stránky btredu a ntredu.
Konverze mezi datovými formáty je velice obtížný úkol, pokud všechny formáty nemohou nést přesně stejné množství informací. Naneštěstí to je právě případ formátů, které vznikly během roků vývoje PDT. Z toho důvodu poskytujeme několik nástrojů, které usnadňují alespoň některé z konverzí. Mohou posloužit i jako příklady složitějších transformací, které mohou být potřebné pro některé úkoly. Úplný popis najdete v textu PDT 2.0: nástroje pro konverzi interních formátů.
V distribuci jsou skripty uloženy v adresáři tools/format-conversions/pdt_formats. Většina těchto skriptů potřebuje ke své činnosti btred, nástroj z balíku TrEd.
Podporovány jsou následující typy konverzí:
K dispozici jsou také skripty pro konverzi formátů Penn Treebanku a korpusu Negra do formátu FS. Konverzní skripty jsou umístěny v adresáři tools/format-conversions/from_negra+ptb. Jejich popis najdete v stručné dokumentaci.
Poznamenejme, že skripty neprovádějí žádnou konverzi anotačních schémat. Jinými slovy, složkové stromy zůstanou složkovými stromy, závislostní struktura není automaticky vytvářena.
Společně s daty poskytujeme také nástroje, které provádějí automatickou anotaci. Ze surových českých vět vytvářejí závislostní stromy na analytické rovině. Nástroje jsou uloženy v adresáři tools/machine-annotation. Provádějí postupně tyto činnosti:
-
rozpoznání slovních jednotek ve vstupním surovém textu a rozdělení textu na věty,
-
morfologickou analýzu a tagging (morfologickou disambiguaci),
-
závislostní parsing,
-
přiřazení analytických (závislostních) funkcí všem uzlům zparsovaného stromu.
Nástroje pro následný parsing na tektogramatickou rovinu zatím neexistují. Prosíme, sledujte webovské stránky http://ufal.ms.mff.cuni.cz/pdt2.0update/ obsahující aktualizace PDT 2.0 a nové nástroje.
Více informací najdete v podrobném popisu nástrojů.
Během vývoje nového parseru je důležité testovat jeho úspěšnost nejen na ručně anotovaných souborech m-roviny, ale také na souborech anotovaných automaticky. Pro nedostatek místa nebylo možné automaticky anotovaná data m-roviny umístit na CD-ROM. K dispozici je však nástroj pro generování dat vhodných pro vývoj parseru a jeho testování.
Tento nástroj je umístěn v adresáři tools/machine-annotation/for_parser_devel/. Spouští se příkazem
run_for_parser_devel vstupní_adresář výstupní_adresář
Vstupní adresář musí mít stejnou strukturu jako adresář data/full/, který bude typicky prvním argumentem nástroje. Nástroj kopíruje celou adresářovou strukturu vstupního adresáře do výstupního adresáře. Kopíruje rovněž všechny datové soubory kromě souborů m-roviny, které jsou nahrazeny soubory nově vytvořenými. Nové soubory m-roviny obsahují automaticky přiřazená lemmata a tagy. Upozorňujeme, že tyto nové soubory nejsou totožné s těmi, které by byly vytvořeny automatickou anotací použitou přímo na prostý text. Zachovávají totiž hranice vět a slovních jednotek a také identifikátory jednotek m-roviny obsažené v ručně anotovaných datech.
Přestože anotátoři viděli každý uzel každého stromu (a to často více než jednou), zůstaly v datech nějaké chyby. Některé byly způsobeny přehlédnutím, jiné tím, že se pravidla anotace během anotačního procesu vyvíjela a měnila, ale data nebyla přeanotována při každé změně. Z toho důvodu bylo během anotační a kontrolní fáze vytvořeno mnoho programů (maker pro TrEd/btred/ntred, viz sekce 4.2 - "Prohlížení stromů: TrEd"), které v datech hledaly porušení nějakého pravidla či invariantu nebo podezřelou anotaci a na každé takové místo upozorňovaly. Data pak byla ručně či automaticky opravena, v případě potřeby bylo makro dále upraveno.
Poznámka
Jako pomůcka při psaní maker pro TrEd slouží dokumentace TrEdu.
Makra byla rozdělena do tří skupin: find, fix a check. Makra ze skupiny find pouze vyhledávala podezřelá místa v datech. Makra ze skupiny fix byla používána pro automatickou opravu dat, pokud byla možná (jako např. když uprostřed anotačního procesu došlo k jasné a jednoznačné změně anotačního pravidla). Poslední skupina (check) obsahovala makra podobná těm ve skupině find, ale zahrnovala seznam výjimek z obecného pravidla. (A existovala vlastně ještě další skupina, nazvaná misc, obsahující směs nejrůznějších dalších maker a skriptů.)
Makra byla dále rozdělena do skupin podle toho, pro kterou rovinu anotace byla určena (viz kapitola 2 - "Roviny anotace" pro další informace o rovinách).
Makra ze skupiny check jsou uložena v adresáři tools/checks.
Varování
Tato makra již nejsou určena k použití na datech, protože formát dat se změnil, ale mohou posloužit k vytvoření jasnější představy, jaké druhy kontrol byly na data v PDT 2.0 aplikovány a jaká makra pro práci se stromy je možno psát.