Obsah
Vlastní data jsou jedinou částí PDT 2.0, kterou si nelze prohlédnout na webovských stránkách PDT, http://ufal.mff.cuni.cz/pdt2.0/. Ke stažení je k dispozici jen část dat (ukázková data, viz sekce 3.7 - "Ukázková data") a PDT-VALLEX (viz sekce 3.8 - "PDT-VALLEX"). Chcete-li získat plná data (viz sekce 3.6 - "Plná data"), včetně aktualizace PDT 1.0 (viz 3.9 - "Aktualizace PDT 1.0"), musíte si opatřit distribuční CD-ROM. Kapitola 7 - "Distribuce a licence" popisuje, jak na to.
Data jsou umístěna v adresáři data.
Data v Pražském závislostním korpusu jsou anotované nezkrácené články z těchto novin a časopisů:
- Lidové noviny (deník), ISSN 1213-1385, 1991, 1994, 1995
- Mladá fronta Dnes (deník), 1992
- Českomoravský Profit (ekonomický týdeník), 1994
- Vesmír (populárně vědecký měsíčník), ISSN 1214-4029, Vesmír, s.r.o., 1992, 1993
Přehled množství dat z jednotlivých zdrojů najdete na obrázku 3.1 - "Počet slovních jednotek (slov, čísel, interpunkce) z jednotlivých zdrojů".
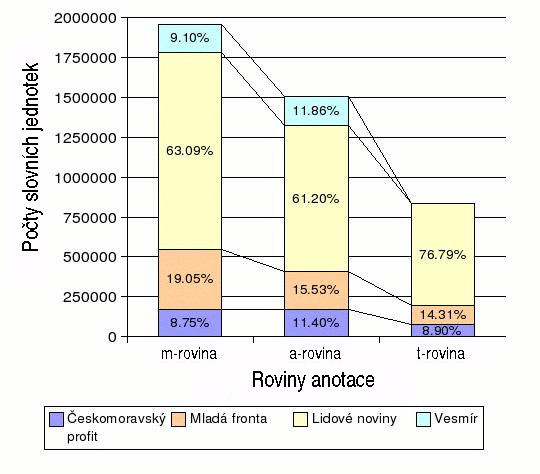
Texty v elektronické podobě poskytl Ústav Českého národního korpusu. Z původních zdrojů přicházely texty v různých podobách. Originální formátování bylo zachováno jen v některých případech, obecně bylo převzato jen rozdělení do dokumentů (článků) a odstavců.
Originální data obsahovala z různých důvodů duplicity (většinou šlo o chybu). Pokud se opakovaly více než tři věty, byly odstraněny. Dále byla odstraněna téměř všechna vysoce četná neslovní data, jako přepisy šachových partií, tabulky výsledků sportovních utkání apod. Několik z nich jsme však zachovali, aby nám připomínaly svou existenci a abychom na nich předvedli navrhovaný (poněkud technický) způsob jejich anotace.
Anotace jednotlivých rovin nepokrývají celá data stejně. Čím vyšší rovina, tím méně dat na ní bylo anotováno. Důvod je zřejmý, anotace složitější roviny vyžaduje více lidské práce, a tedy více času a peněz. Existují ještě další technologické důvody: při určitém způsobu vývoje nástrojů pro vyšší roviny musí pro potřeby trénování existovat více dat na nižší rovině, jejíž anotace na vyšší rovině stejně nemůže být použita. Platí, že každý soubor, anotovaný na některé rovině, je anotován rovněž na všech rovinách nižších. Situaci ilustruje obrázek 3.2 - "Rozdělení dat do rovin".
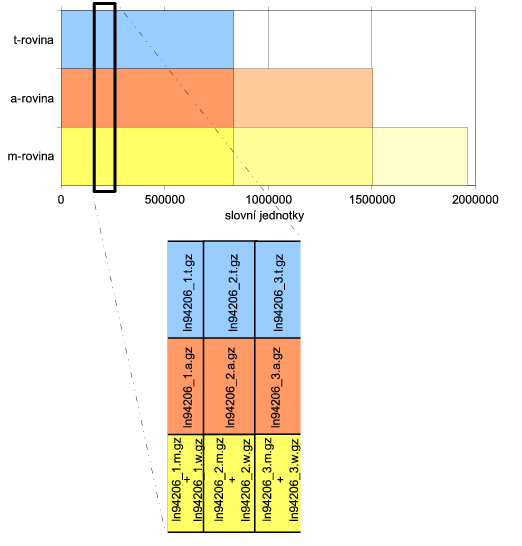
Další informace o rovinách najdete v kapitole 2 - "Roviny anotace". Informace o jmenné konvenci souborů, odrážející roviny anotace, najdete v sekci 3.5 - "Konvence pojmenování souborů". Podrobné informace o množství dat najdete v sekci 3.6 - "Plná data".
Data jsou rozdělena, jak je obvyklé, do tří skupin: trénovací data (train), vývojová testovací data (dtest) a evaluační testovací data (etest). Trénovací data tvoří přibližně 80% celkového množství dat, vývojová 10% a evaluační rovněž 10% (tento poměr platí na všech rovinách anotace).
Uživatelé mohou libovolně využívat trénovací data a prověřovat své hypotézy nebo nástroje na vývojových testovacích datech. Na evaluační testovací data by se neměli dívat nikdy, ta jsou určena výhradně pro evaluace. I tak by evaluační data měla být používána s rozvahou a co nejméně, neboť pozorování získaná opakovanými testy by mohla vést ke změně původní hypotézy či nástroje, a tak by evaluační data začala sloužit jako vývojová testovací data.
Poměr train/dtest/etest je přibližně stejný jako v PDT 1.0 (8:1:1), ale z různých důvodů nebylo zachováno staré rozdělení dat. Data v PDT 2.0 byla rozdělena následujícím způsobem: dokumenty morfologické roviny byly brány postupně a cyklicky rozdělovány, první byl vložen do množiny train-1, druhý do train-2, a tak dále až po train-8, devátý byl vložen do dtest a desátý do etest. Jedenáctý dokument připadl opět do train-1 atd. (Rozdělení trénovací množiny do osmi podmnožin bylo provedeno proto, aby se zmenšil počet souborů v adresářích; existence deseti stejně velkých množin dat může navíc sloužit pro experimenty s křížovou validací.) Dokumenty anotované na ostatních rovinách připadly do stejných množin jako jejich morfologicky anotované verze. Díky sekvenčnímu výběru dokumentů pro anotaci tento algoritmus zaručuje, že poměr rozdělených dat zůstane i na vyšších rovinách téměř stejný (8:1:1), s malou odchylkou způsobenou rozdílem ve velikosti souborů.
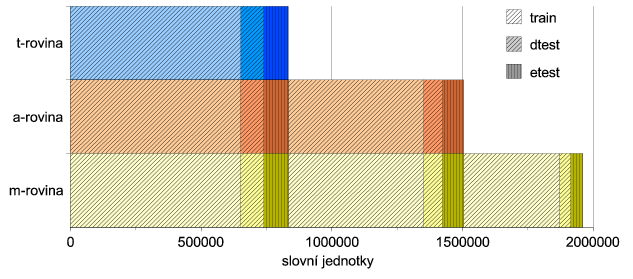
Obrázek 3.3 - "Rozdělení dat na trénovací a testovací množiny" ukazuje rozdělení dat. Algoritmus použitý k rozdělení zaručuje, že každý soubor patří do stejné množiny (train, dtest, etest) na všech rovinách, na kterých je anotován. (Podrobné informace o množství dat najdete v sekci 3.6 - "Plná data".)
Poznamenejme, že uživatel, který provádí experiment např. na datech a-roviny a tento experiment se netýká t-roviny, by měl použít takové rozdělení dat, které nebere v úvahu, zda jsou daná data anotována na t-rovině či ne. Díky tomu je např. množina etest na a-rovině ve skutečnosti složena ze dvou částí, jak je vidět na obrázku 3.3 - "Rozdělení dat na trénovací a testovací množiny" (dvě svisle šrafované oblasti ve středním sloupci). Podobně je množina train-1 m-roviny složena ze tří částí. O těchto rozděleních pojednává rovněž sekce 3.6 - "Plná data".
Hlavním formátem dat v PDT 2.0 je formát nazvaný PML, který je založený na XML. Během vývoje PDT vznikly a byly používány ještě dva další formáty dat. Formát FS byl vytvořen pro vyhledávací program Netgraph (přísně vzato vlastně pro jeho předchůdce, editor Graph). Formát zvaný CSTS, založený na SGML, byl hlavním formátem dat v PDT 1.0. Nyní je používán jen jako přechodný formát pro kompatibilitu se staršími nástroji pro zpracovnání jazyka (taggery, parsery, ...).
Informace o konverzích mezi těmito formáty najdete v sekci 4.4.1 - "Konverze mezi formáty PDT".
PML ("Prague Markup Language") je formát dat založený na XML, navržený pro reprezentaci bohaté lingvistické anotace textů, jako jsou morfologické značkování, závislotní stromy apod. PML je probíhající projekt ve své rané fázi. Přesto je již dostatečně pokročilý, aby umožnil přiměřenou a snadnou reprezentaci dat v PDT 2.0. Následující text obsahuje stručný přehled hlavních vlastností PML. Podrobné informace o tomto formátu najdete v dokumentaci PML. Informace o tom, jak jsou data PDT 2.0 reprezentována v PML, najdete v příručce anotačních značek PDT 2.0.
V PML se mohou jednotlivé oddělené roviny anotace překrývat a mohou být konzistentně propojeny jak mezi sebou, tak i s dalšími zdroji dat. Každá rovina anotace je popsána v souboru PML schéma, který je jakousi formalizací abstraktního anotačního schématu pro tu konkrétní rovinu anotace. PML schéma popisuje, které elementy se na dané rovině vyskytují, jak jsou spojovány, vnořovány a strukturovány, hodnoty jakého typu se v nich mohou vyskytovat a jakou roli hrají v anotačním schématu (tato informace o PML-roli může být využívána i aplikacemi ke správnému určení způsobu zobrazení PML dat uživateli). Z PML schématu mohou být automaticky generována další schémata, jako je Relax NG, díky čemuž může být konzistence dat ověřena pomocí běžných nástrojů pro XML (XSLT styl pro konverzi PML schématu do Relax NG je k dispozici v tools/pml/pml2rng.xsl).
Každý PML soubor začíná hlavičkou, odkazující na PML schéma souboru. V hlavičce jsou uvedeny všechny externí zdroje, na které je z tohoto souboru odkazováno, spolu s několika dalšími informacemi, potřebnými pro správné vyhodnocení odkazů. Zbytek souboru obsahuje vlastní anotaci.
Anotace je vyjádřena pomocí XML elementů a atributů, pojmenovaných a použitých v souladu s příslušným PML schématem. XML elementy všech souborů patří do vyhrazeného jmenného prostoru http://ufal.mff.cuni.cz/pdt/pml/. Formát PML poskytuje jednotnou reprezentaci většiny běžných anotačních konstrukcí, jako jsou struktury atribut-hodnota, seznam alternativních hodnot určitého typu (atomického nebo dále strukturovaného), odkazy v rámci PML souboru, odkazy mezi různými PML soubory (v PDT 2.0 použité k odkazům mezi rovinami) nebo do dalších externích zdrojů typu XML. V současné verzi nabízí PML i omezenou podporu XML elementů se smíšeným obsahem. Abychom se vyhnuli možné záměně s atributy XML, nazýváme obvykle atributy sktruktury atribut-hodnota prvky.
Anotace PDT 2.0 je rozdělena do čtyř rovin, naskládaných jedna na druhou, a to roviny slovní, morfologické, analytické a tektogramatické (viz kapitola 2 - "Roviny anotace"). Každá z těchto rovin má vlastní PML schéma.
Tektogramatické a analytické stromy jsou v PML reprezentovány běžným způsobem jako vnořené struktury atribut-hodnota. Uzel stromu je reprezentován strukturou atribut-hodnota s PML-rolí #NODE. Každý uzel má prvek s PML-rolí #CHILDNODES, který obsahuje seznam přímých potomků daného uzlu. Technický kořen závislostních stromů v PDT 2.0 slouží zvláštním pomocným účelům, a proto je jeho struktura odlišná od ostatních uzlů (má jiné prvky).
Obsáhlé informace o reprezentaci čtyř anotačních rovin v PML najdete v Příručce anotačních značek PDT 2.0 . PML a Relax NG schémata pro čtyři anotační roviny najdete v adresáři data/schemas.
Formát PML, založený na XML, je primárním formátem dat v PDT 2.0. Při práci s ním však nástroje TrEd a btred, založené na Perlu, spotřebují mnoho času načítáním dat a jejich převodem do vnitřní paměťové reprezentace. Této časově náročné transformaci se lze vyhnout využitím formátu pls.gz (Perl Storable Format). Jde o binární datový formát, který přímo odráží vnitřní paměťovou reprezentaci dat v Perlu. Jeho ukládání a zpětné načítání je tedy mnohem rychlejší. Není ale založen na XML, a nelze jej tedy snadno použít jinými nástroji.
Formát FS ("feature structure") je formát souborů pro reprezentaci stromů, jejichž uzly jsou sktruktury atribut-hodnota. Může být chápán jako "meta formát", podobně jako SGML nebo XML. Konkrétní použití tohoto formátu je plně specifikováno deklarací atributů v hlavičce FS souboru (hlavička FS souboru tak hraje podobnou roli jako DTD u SGML souboru).
FS soubor začíná deklarací atributů. Každá řádka deklarace sestává ze znaku @, vlastnosti atributu, mezery a jména atributu. Např. vlastnost O, "obligatory", označuje povinný atribut, tedy atribut, jehož hodnota musí být u každého uzlu neprázdná. Vlastnost L, "list", označuje výčtový atribut, tedy atribut, jehož hodnota u každého uzlu (pokud je neprázdná) musí být jednou z hodnot uvedených v seznamu následujícím za jménem atributu v hlavičce. Úplný popis najdete ve specifikaci FS formátu.
Deklarační hlavička končí prázdným řádkem, po němž následují popisy stromů anotace. Každý strom začíná na novém řádku. Stromy jsou popsány v obvyklé závorkové notaci, tj. po popisu uzlu následuje seznam jeho přímých potomků, uzavřený v závorkách. Jednotliví potomci jsou odděleni čárkou. Popis každého uzlu je uzavřen v hranatých závorkách a sestává ze seznamu dvojic atribut=hodnotaP), může být u uzlu určen jen svou hodnotou a jeho jméno je odvozeno z předchozích známých atributů a z pořadí atributů v hlavičce.
CSTS ("Czech sentence tree structure"), formát založený na SGML, byl hlavním formátem dat v PDT 1.0. Ačkoliv byl v PDT 2.0 nahrazen PML, některé nástroje jej stále výhradně používají. CSTS může reprezentovat jen morfologickou a analytickou anotaci (abychom byli přesní, jeho definice obsahuje i několik elementů vztahujících se k tektogramatické anotaci, ale není schopen plného popisu t-roviny). Velmi doporučujeme používat místo něj PML (viz sekce 3.4.1 - "PML"), kdykoliv je to možné. To se týká zejména nových nástrojů. Více informací najdete v úplném popisu CSTS a jeho DTD souboru.
Data v PDT 2.0 jsou distribuována ve formátu PML (viz popis PML v sekci 3.4.1 - "PML"). Každý datový soubor odpovídá jednomu anotovanému dokumentu. Základem jeho jména je identifikátor dokumentu (indikuje také zdroj dokumentu, viz sekce 3.1 - "Zdroje textů": ln* označuje Lidové noviny, mf* označuje Mladou frontu Dnes, vesm* označuje Vesmír a cmpr* označuje Českomoravský profit). Přípona souboru vyjadřuje rovinu anotace dokumentu (.w označuje w-rovinu, .m označuje m-rovinu, .a označuje a-rovinu a .t označuje t-rovinu). (Popis rovin najdete v kapitole 2 - "Roviny anotace".)
Každý soubor obsahující anotaci dokumentu na nějaké rovině odpovídá jedna ku jedné souborům obsahujícím anotace nižších rovin téhož dokumentu a obsahuje reference do těchto souborů. Z tohoto důvodu by soubory neměly být přejmenovány. Z nižších rovin anotace do vyšších rovin odkazy nevedou. Přehled propojení rovin najdete na obrázku 2.1 - "Propojení rovin".
Příklad: cmpr9406_001.a.gz označuje soubor (zkomprimovaný gzip-em) obsahující a-rovinu anotace dokumentu cmpr9406_001 (pocházejícího z Českomoravského profitu). Ze souboru vedou odkazy do souborů cmpr9406_001.m.gz a cmpr9406_001.w.gz; z těchto údajů však nelze odvodit existenci souboru cmpr9406_001.t.gz.
Podle jména souboru se nepozná, zda soubor patří do trénovací nebo testovací množiny. To je dáno umístěním souboru v adresářové struktuře, viz sekce 3.3 - "Rozdělení dat na trénovací a testovací".
Ze jmen souborů jsou odvozena také jména identifikátorů vět a prvků vět, obsažených v těchto souborech. Každý identifikátor je jedinečný v rámci celého korpusu.
Plná verze dat PDT 2.0 je k dispozici oprávněným uživetelům, kteří CD-ROM PDT 2.0 získali z Linguistic Data Consortium (viz kapitola 7 - "Distribuce a licence"). Malá ukázka dat může být volně stažena z internetu (viz sekce 3.7 - "Ukázková data").
Plná verze dat PDT 2.0 sestává ze 7 110 ručně anotovaných textových dokumentů, obsahujících celkem 115 844 vět s 1 957 247 slovními jednotkami (slovy, čísly, interpunkcí). Všechny tyto dokumenty jsou anotovány na m-rovině. 75% dat m-roviny je anotováno rovněž na a-rovině (5 330 dokumentů, 87 913 vět, 1 503 739 slovních jednotek). 59% dat a-roviny je anotováno také na t-rovině (tj. 45% dat m-roviny; 3 165 dokumentů, 49 431 vět, 833 195 slovních jednotek).
Plná data ve formátu PML jsou uložena v adresáři data/full na CD-ROM PDT 2.0. (Pro rychlejší zpracování nástroji založenými na TrEdu jsou plná data, anotovaná alespoň na a-rovině, převedena rovněž do formátu Perl Storable Format; tato data jsou uložena v adresářích data/binary/amw a data/binary/tamw.) Datové soubory jsou rozděleny podle této dvoustupňové hierarchie:
-
První větvení odpovídá nejvyšší vrstvě anotace (viz kapitola 2 - "Roviny anotace") dostupné pro daný dokument:
-
data/full/tamw/- dokumenty anotované na všech rovinách, -
data/full/amw/- dokumenty anotované pouze na m-rovině a a-rovině, -
data/full/mw/- dokumenty anotované pouze na m-rovině.
-
-
Obsah každého z těchto tří adresářů je dále rozdělen do deseti přibližně stejně velkých částí (viz sekce 3.3 - "Rozdělení dat na trénovací a testovací"). Osm z nich slouží pro trénovací účely (
train-1/ažtrain-8/), jedna pro vývojové testy (dtest/) a jedna pro evaluační testy (etest/).
Přestože jsou data takto rozdělena do třiceti adresářů, zůstává množství souborů v jednotlivých adresářích stále značné. To je způsobeno částečně tím, že počet fyzických souborů (v porovnání s počtem původních textových dokumentů) je v případě tamw dat násoben čtyřmi (pro každý dokument jsou v adresáři čtyři soubory, obsahující jeho anotaci na jednotlivých rovinách, viz sekce 3.5 - "Konvence pojmenování souborů"), třemi v případě amw dat a dvěma u mw dat. Tak se celkový počet datových souborů rovná 4 x 3 165 + 3 x 2 165 + 2 x 1 780 = 22 715. Například adresář data/full/tamw/train-3/ obsahuje 4 x 317 = 1 268 datových souborů.
Poznamenejme, že se žádný datový soubor nevyskytuje v adresáři data/full/ dvakrát (např. soubory *.m z data/full/amw/ se již neobjeví v data/full/mw/). Všech třicet podadresářů má vzájemně se nepřekrývající obsah, soubory v těchto adresářích obsahují anotace různých textů.
Podrobný rozpis množství dat v jednotlivých adresářích, rozdělených podle výše uvedených zásad, najdete v tabulkách 3.1 - "Data anotovaná na všech vrstvách (tamw). ", 3.2 - "Data anotovaná pouze na m-rovině a a-rovině (amw). " a 3.3 - " Data anotovaná pouze na m-rovině (mw). ".
Tabulka 3.1. Data anotovaná na všech vrstvách (tamw).
tamw |
train | dtest | etest | celkem |
|---|---|---|---|---|
|
Umístění na CD-ROM |
... |
tamw/dtest/ |
tamw/etest/ |
tamw/*/ |
|
# dokumentů |
2 533 (80,0%) |
316 (10,0%) |
316 (10,0%) |
3 165 (100,0%) |
|
# vět |
38 727 (78,3%) |
5 228 (10,6%) |
5 476 (11,1%) |
49 431 (100,0%) |
|
# slovních jednotek |
652 544 (78,3%) |
87 988 (10,6%) |
92 663 (11,1%) |
833 195 (100,0%) |
Tabulka 3.2. Data anotovaná pouze na m-rovině a a-rovině (amw).
amw |
train | dtest | etest | celkem |
|---|---|---|---|---|
|
Umístění na CD-ROM |
... |
amw/dtest/ |
amw/etest/ |
amw/*/ |
|
# dokumentů |
1 731 (80,0%) |
217 (10,0%) |
217 (10,0%) |
2 165 (100,0%) |
|
# vět |
29 768 (77,4%) |
4 042 (10,5%) |
4 672 (12,1%) |
38 482 (100,0%) |
|
# slovních jednotek |
518 647 (77,3%) |
70 974 (10,6%) |
80 923 (12,1%) |
670 544 (100,0%) |
Tabulka 3.3. Data anotovaná pouze na m-rovině (mw).
mw |
train | dtest | etest | celkem |
|---|---|---|---|---|
|
Umístění na CD-ROM |
... |
mw/dtest/ |
mw/etest/ |
mw/*/ |
|
# dokumentů |
1 422 (79,9%) |
179 (10,1%) |
179 (10,1%) |
1 780 (100,0%) |
|
# vět |
22 333 (80,0%) |
2 610 (9,3%) |
2 988 (10,7%) |
27 931 (100,0%) |
|
# slovních jednotek |
364 640 (80,4%) |
42 689 (9,4%) |
46 179 (10,2%) |
453 508 (100,0%) |
Ti, kdo chtějí pracovat pouze s daty m-roviny nebo a-roviny bez ohledu na to, zda jsou dané dokumenty anotovány také na vyšších rovinách, by měli použít jiné rozdělení. Například při experimentech se všemi daty m-roviny by měla trénovací data sestávat ze všech souborů data/full/{tamw,amw,mw}/train-[1-8]/*m.gz.
Počty všech dokumentů anotovaných na m-rovině (bez ohledu na to, zda existují jejich anotace na a-rovině a t-rovině) jsou sečteny v tabulce 3.4 - "Alternativní rozdělení: Všechny dokumenty anotované na m-rovině (sjednocení tamw, amw a mw). ". Všechny dokumenty anotované na a-rovině (bez ohledu na to, zda existuje jejich anotace na t-rovině) jsou posčítány v tabulce 3.5 - "Alternativní rozdělení: Všechna data anotovaná na a-rovině (sjednocení tamw a amw). ".
Tabulka 3.4. Alternativní rozdělení: Všechny dokumenty anotované na m-rovině (sjednocení tamw, amw a mw).
all_m |
train | dtest | etest | celkem |
|---|---|---|---|---|
|
Umístění na CD-ROM |
...
|
*/dtest/ |
*/etest/ |
*/*/ |
|
# dokumentů |
5 686 (80,0%) |
712 (10,0%) |
712 (10,0%) |
7 110 (100,0%) |
|
# vět |
90 828 (78,4%) |
11 880 (10,3%) |
13 136 (11,3%) |
115 844 (100,0%) |
|
# slovních jednotek |
1 535 831 (78,5%) |
201 651 (10,3%) |
219 765 (11,2%) |
1 957 247 (100,0%) |
Tabulka 3.5. Alternativní rozdělení: Všechna data anotovaná na a-rovině (sjednocení tamw a amw).
all_a |
train | dtest | etest | celkem |
|---|---|---|---|---|
|
Umístění na CD-ROM |
...
|
*a*/dtest/ |
*a*/etest/ |
*a*/*/ |
|
# dokumentů |
4 264 (80,0%) |
533 (10,0%) |
533 (10,0%) |
5 330 (100,0%) |
|
# vět |
68 495 (77,9%) |
9 270 (10,5%) |
10 148 (11,5%) |
87 913 (100,0%) |
|
# slovních jednotek |
1 171 191 (77,9%) |
158 962 (10,6%) |
173 586 (11,5%) |
1 503 739 (100,0%) |
Není jistě třeba dodávat, že každý zveřejněný experiment provedený na datech PDT 2.0 by měl obsahovat informaci o tom, jaká část dat byla pro jaký účel v experimentu použita.
Práci s velkým počtem datových souborů pomohou usnadnit předgenerované seznamy souborů, umístěné jako samostatné soubory v adresáři data/filelists/; jsou užitečné nejen při práci s programy tred/btred/ntred, ale i na příkazové řádce, kde odstraní problém s příliš velkým počtem argumentů. Připraveno je pouze několik základních seznamů souborů, uživatel má možnost snadno si vytvořit jakýkoliv jemu vyhovující další seznam souborů, odpovídající libovolné podmnožině všech dat (viz též tutoriál k btred/ntredu).
Malá část plných dat je k dispozici ke stažení na internetu (připomeňme, že postup k získání plné verze dat najdete v kapitole 7 - "Distribuce a licence"). Data jsou rozdělena do deseti skupin (sample0 až sample9) přibližně po 50 větách. Každá skupina sestává ze čtyř souborů (sampleX.w.gz, sampleX.m.gz, sampleX.a.gz a sampleX.t.gz); přípona souboru vyjadřuje rovinu anotace (viz sekce 3.5 - "Konvence pojmenování souborů"). Ukázková data jsou tvořena úseky vybranými náhodně z plných dat (viz sekce 3.6 - "Plná data").
Ukázková data jsou umístěna v adresáři data/sample. Ve stejném adresáři najdete i archív všech ukázkových souborů. Pokud si nemůžete nebo nechcete nainstalovat nástroje pro práci s daty ve formátu PML (viz kapitola 4 - "Nástroje"), můžete si ukázková data snadno prohlédnout v podobě webovských stránek.
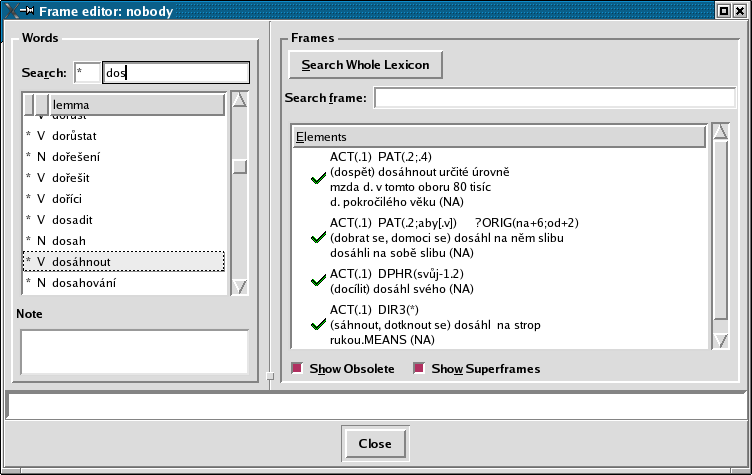
PDT 2.0 obsahuje také omezenou lexikálně-sémantickou anotaci, která nově provazuje hloubkovou a povrchovou syntax a morfologii pomocí valenčního slovníku, zvaného PDT-VALLEX. Valenční slovník najdete v adresáři data/pdt-vallex ve formátu XML (viz jeho popis) nebo si ho můžete prohlédnout v podobě webovských stránek- viz zobrazení jedné jeho položky na obrázku 3.4 - "Ukázka položky PDT-VALLEXu ve formátu pro zobrazení".

Položky PDT-VALLEXu obsahují jednotlivé významy sloves a některých slovesných podstatných a přídavných jmen, které se vyskytují v korpusu. Každý význam obsahuje valenční rámec se sémantickou, syntaktickou a morfologickou informací o jeho sémanticky povinných a/nebo volitelných závislých členech.
Každý valenční rámec obsahuje nula nebo více valenčních pozic. Každá pozice má syntaktickou nebo sémantickou značku (např. ACT, PAT, ADDR, LOC, AIM, CRIT, BEN atd.; více obecných informací o tektogramatickém anotování najdete v textu Tektogramatická anotace PDT: pokyny pro anotátory), a je označena buď jako povinná (obligatorní) nebo jako volitelná (fakultativní). Pozice navíc obsahují povrchově syntaktickou a morfologickou informaci o své povrchové realizaci (výrazu), jako je morfologický pád, předložka, která má být použita s příslušnou lexikální jednotkou, nebo (v případě frázémů) celý syntaktický podstrom, který frazém na povrchu vytváří.
Nejdůležitější vlastností PDT-VALLEXu však je, že každý výskyt slovesa či slovesného podstatného jména v PDT 2.0 je provázán (s použitím zvlášního referenčního atributu) z korpusu na položku slovníku, čímž je vlastně provedena anotace významů těchto slov (word sense annotation). Položky slovníku, jejich značky, obligatornost/fakultativnost a povrchové morfologické formy byly zkontrolovány, aby plně souhlasily se všemi daty korpusu na všech rovinách anotace.
K dispozici jsou i nástroje, které umožňují spojení mezi korpusem a slovníkem využít (umožňují průběžné prohlížení, vyhledávání a editaci v editoru TrEd, viz obrázek 3.5 - "PDT-VALLEX v editoru TrEd").
Hlavní rozdíl mezi PDT 1.0 a PDT 2.0 spočívá v přítomnosti anotace na tektogramatické rovině (viz sekce 2.3 - "Tektogramatická rovina"). Mnoha změn však doznaly i nižší roviny. Pro uživatele PDT 1.0 jsme připravili aktualizaci dat, která k originálním datům přidává všechny změny a nové informace. Aktualizace je umístěna v adresáři data/pdt1.0-update. Aktualizační balík je určen pouze pro formát CSTS, staré FS soubory jím nemohou být aktualizovány.
Změny zahrnují:
- opravy různých chyb na morfologické a analytické rovině,
- opravy překlepů,
- přidání ruční morfologické anotace ve všech souborech.
Požadavky pro aplikaci aktualizačního balíku. Pro aktualizaci dat potřebujete dva GNU nástroje, gunzip a patch. V linuxových distribucích bývají tyto nástroje obvykle již instalovány. Používáte-li MS Windows, stáhněte si z internetu GNU patch (jiné verze by nemusely fungovat). gunzip pro Windows můžete použít jak ve verzi z distribuce Cygwin, tak i ze stránek GNU. Na CD-ROM PDT 2.0 najdete kopii nástroje gunzip.exe z distribuce Cygwin v adresáři tools/tred/bin/.
Aplikování aktualizačního balíku na všechny datové adresáře. PDT 1.0 CD-ROM obsahuje několik překrývajících se (ve smyslu pevných odkazů) podmnožin dat v podadresářích adresáře PDT_1.0_CD-ROM/Corpora/PDT_1.0/Data/fs/ a fs-am/. Pro současnou aktualizaci všech těchto podadresářů na Linuxu použijte skript data/pdt1.0-update/linux-apply-patch.sh. Skript spusťte a pokračujte podle instrukcí. V případě MS Windows nemůžeme poskytnout zaručený způsob, jak aktualizaci automaticky aplikovat na všechny datové adresáře. Postupujte podle instrukcí níže uvedených a aktualizujte jednotlivé adresáře postupně.
Aplikování aktualizačního balíku na jeden datový adresář.
- Zkopírujte soubory z vybraného podadresáře
Corpora/PDT_1.0/Data/(kromě podadresářůfs/afs-am/) na disku PDT 1.0 do nějakého nového pracovního adresáře. - Přejděte do tohoto adresáře: cd
pracovní_adresář - Rozbalte všechny soubory: gunzip *.gz
-
Aplikujte aktualizační balík: gunzip -c
PDT_2.0_CD-ROM/data/pdt1.0-update/pdtpatch.gz | patch -p1 -tPřepínač
-tje vyžadován v případě aktualizace neúplných adresářů, tedy např. adresářů, které neobsahují všechny datové soubory PDT 1.0. Tento přepínač říká nástrojipatch, že má přeskočit všechny neexistující soubory bez dotazování se uživatele. V MS Windows přidejte k příkazu patch přepínač--binary, jinak by aktualizace mohla selhat.