Prague Czech-English Dependency Treebank 3.0
PCEDT 3.0
Introduction
The PCEDT 3.0 version has not yet been published. The latest published version is PCEDT 2.0Coref.
The Prague Czech-English Dependency Treebank 3.0 (PCEDT 3.0) is a major update of the Prague Czech-English Dependency Treebank 2.0 and the Prague Czech-English Dependency Treebank 2.0 Coref. It is a manually parsed Czech-English parallel corpus sized over 1.2 million running words in almost 50,000 sentences for each part. Each language part encompass a comprehensive manual linguistic annotation (called tectogrammatical) in the traditional PDT-style.

Figure 1
The diffrerences from the previous published versions are :
- the Czech data is enhanced with a manual linguistic annotation at the morphological layer and new version of morphological dictionary is enclosed;
- each language part is uniformly published in three formats (pml, treex, mrp; see Data);
- updated versions of the valency lexicons for each language part are enclosed (PDT-Vallex 4.0 and EngVallex 2.0);
- a number of errors have been corrected, especially errors in tokenization: words written with a hyphen (ex. Hewlett-Packard) or a number (ex. 30bodový ´30-point´ ) are tokenized into separate tokens: the part before the hyphen/number, the hyphen/number and the part after the hyphen/number.
The Czech part of the PCEDT corpus is also contained in the consolidated PDT-C 1.0 release.
Data
The English part contains the entire Penn Treebank - Wall Street Journal Section (LDC99T42). The Czech part consists of Czech translations of the Penn Treebank - Wall Street Journal texts. The corpus is 1:1 sentence-aligned. An additional automatic alignment on the node level (different for each annotation layer) is part of this release, too. The original Penn Treebank-like file structure (25 sections, each containing up to one hundred files) has been preserved. Only those Penn Treebank documents which have both POS and structural annotation (total of 2312 documents) have been translated to Czech and made part of this release.
Table 1 presents an overview of various types of annotation at the three annotation layers in each language part and the information of the manner in which the annotations were carried out.
|
Dataset/Type of annotation |
Czech part |
English part |
|
Translation |
manually |
- |
|
m-layer |
||
|
Lemmatization |
manually |
manually |
|
Tagging |
manually |
manually |
|
a-layer |
||
|
Dependency structure |
automatically |
automatically |
|
Surface syntax functions |
automatically |
automatically |
|
Alignment |
- |
automatically |
|
t-layer |
||
|
Deep syntactic structure |
manually |
manually |
|
Deep syntactic functions |
manually |
manually |
|
Verbal valency |
manually |
manually |
|
Valency lexicon |
manually |
|
|
Coreference grammatical |
manually |
manually |
|
Coreference textual |
manually |
manually |
|
-- pronominal |
manually |
manually |
|
-- nominal |
manually |
manually |
|
-- split antecedent |
manually |
manually |
|
Grammatemes |
automatically |
automatically |
|
Formemes |
automatically |
automatically |
|
Nombank data |
- |
provided |
|
BBN Entity type |
- |
provided |
|
Alignment |
- |
automatically |
|
p-layer |
||
|
Original PTB annotation |
- |
provided |
Table 1. Overview of various types of annotation and their realization in the corpus
Layers of Annotation
The PDT-annotation scheme has a multi-layer architecture:
- morphological layer (m-layer),
- surface syntax layer (analytical, a-layer),
- deep syntax layer (tectogrammatical, t-layer).
In addition to the above-mentioned three annotation layers in the PDT-scenario, there is also the raw text layer (w-layer) where the text is segmented into documents and paragraphs and individual tokens are assigned unique identifiers (ID attribute).
In order not to lose any piece of the original information, tokens (nodes) at a lower layer are explicitly referenced from the corresponding closest (immediately higher) layer. These links allow for tracing every unit of annotation all the way down to the original text.
The English part also contains the original Penn Treebank annotation, which we call p-layer (phrase-structure layer).
m-layer
At the m-layer (morphological layer), the tokens are tagged and lemmatized. From this point on, we can regard the tokens as linearly ordered nodes with their respective IDs, tags and lemmas. In the corpus, the m-layer is not visualized separately but rather as a part of the a-layer.
At English part, the morphological tags contain only POS value taken from the original Penn Treebank POS annotation (see Part-of-Speech Tagging Guidelines for PennTreebank). For comprehensive specification of the Czech morphological annotation see the manual of the Czech morphological annotation.
a-layer
The a-layer (analytical layer) represents the surface syntax (a parse). The syntactic dependencies are provided with labels that carry the usual syntactic information; e.g. "subject", "attribute" or "predicate complement". For more details see a comprehensive specification of the Czech manual analytical annotation and also a brief specification of the English analytical annotation (see Documentation for other formats and version). Figure 2 presents the visualization of an analytical sentence representation in TrEd.
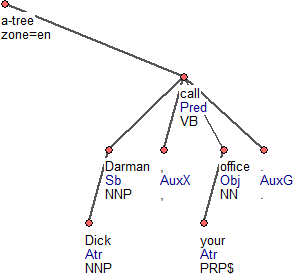
Figure 2
t-layer
The topmost - tectogrammatical - layer is a linguistic representation that combines syntax and, to a certain extent, semantics, in the form of semantic labeling, anaphora resolution and argument structure description based on a valency lexicon. For more details see a comprehensive specification of the Czech tectogrammatical annotation and also brief specification of the English tectogrammatical annotation. More information about coreference annotation can be found here. More information about so-called formemes can be found here. See Documentation for other formats and version. Figure 3 shows a tectogrammatical sentence representation visualized in the Tree editor TrEd (see Data).

Figure 3
p-layer
The original PennTreebank annotation is displayed as an additional layer of the corpus (see Bracketing Guidelines for PennTreebank). This layer is not aligned with any of the Czech parts (layers) of the corpus. The original bracketing was converted into the PML format so that it can be viewed and processed by the annotation tool TrEd. Each node was assigned its unique ID. All original attribute values were preserved. Figure 4 presents an example of a PennTreebank sentence, as displayed by TrEd. Terminal nodes that represent tokens are yellow, while traces are grey. Labels of non-terminal nodes are displayed as well. POS-tags are attached to the terminal nodes, instead of being treated as separate pre-terminals. The tokens are in addition lemmatized (but by default not displayed).
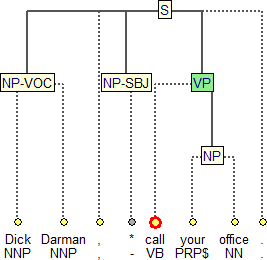
Figure 4
Annotation of the Czech part
Sentences of the Czech translation were manually morphologically annotated and automatically parsed into surface-syntax dependency trees in the PDT-annotation style (a-layer). The manual tectogrammatical (deep-syntax) annotation was built as a separate layer above the automatic analytical (surface-syntax) parse. Compared to the complex Prague Dependency Treebank, the tectogrammatical annotation in PCEDT 3.0 is slightly simplified, e.g. it does not contain the topic-focus (information structure) annotation for either language (see more here).
Annotation of the English part
The resulting manual tectogrammatical annotation was built above an automatic transformation of the original phrase-structure annotation of the Penn Treebank into surface dependency (a-layer) representations (more information about obtaining the analytical parse for English can be found here).
The annotation of the English part was built using the following additional linguistic information from other sources:
- PropBank OntoNotes 4.0 release (LDC2011T03): The English lexicon EngVallex contains mapping to the then-current version of PropBank (see PropBank Annotation Guidelines). EngVallex-to-PropBank mapping is described here.
- VerbNet: The dictionary was available for annotators during the annotation of the t-layer.
- NomBank (LDC2008T23): The NomBank annotation (described in the Annotation guidelines for NomBank) is stored at the tectogrammatical layer at the nombank_data attribute.
- Noun Phrase Bracketing System by courtesy of D. Vadas and J.R. Curran (2011).
- BBN Pronoun Coreference and Entity Type Corpus (LDC2005T33): The coreference annotation on the English part of PCEDT was built above an automatic transformation of the original coreference annotation extracted from the BBN Pronoun Coreference and Entity Type Corpus described in the OntoNotes coreference guidelines. It was further manually checked and corrected. More details can be found here.
- The BBN entity types are stored at the bbn_tag attributte.
For each sentence, the original Penn Treebank phrase structure trees (p-layer) are preserved in this corpus. This layer is not aligned with any of the Czech parts (layers) of the corpus.
Alignment
PCEDT 3.0 is an automatically word-aligned parallel corpus. The alignment is directed from the English part to the Czech part, for each layer (a-layer and t-layer) separately. The English annotation layers contain the alignment information in the form of references from English nodes to their corresponding Czech nodes (in the alignment attribute). Figure 1 (above) and Figure 5 present the alignment at the respective layers of annotation.
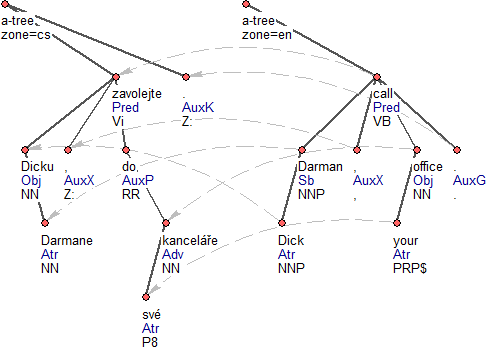
Figure 5