Table of Contents
The tools are programmed in C/C++ and Perl and the execution scripts in tcsh. Mainly for copyright reason we do not distribute C/C++ source codes. The executables are compiled for Linux running on i386 architecture.
The only information written on the screen during the processing of scripts are starting and ending time and the name of a processed file. Reports about processing, including warnings and errors, are written into a log file-it is stored in every output directory of every tool and its name is the same as that of the directory with extension .log.
Please, pay attention to technical details described in the text bellow (regarding e.g. input encoding and viewing output files in TrEd), otherwise things might not work as expected.
In this phase, the input text is tokenized (divided into words and punctuation) and segmentized (i.e. sequences of tokens are divided into sentences).
The tokenizer and the segmentizer work together. The guiding principle for tokenization is to separate any questionable sequences of symbols as much as possible; for example, hyphens and apostrophes are always treated as separators (and, of course, they become tokens by themselves as well). For the segmentizer, various lists are used to guide its decisions for making a sentence break, since in Czech, the full-stop (".") usage is very ambiguous (for example, it also denotes ordinal numerals written in digits). Such lists include common abbreviations with compulsory full-stop at the end, named entities that can/cannot end a sentence, etc. Numbers in digits are recognized and normalized (period is used instead of a Czech-standard comma in decimal numbers). Finally, the text is marked up in CSTS.
Error rate. Tested on all but tectogrammaticaly annotated data, precision, recall, and F-measure of segmentation are 98.0%, 91.4%, and 94.6%, respectively. On the same data, precision, recall, and F-measure of tokenization is 100.0%, 99.2%, and 99.6%, respectively.
Execution. The tool is run by the command
run_tokenizer output_directory filepath(s)
The files with the given path(s) are processed and copied into the given directory (it does not need to exist), no its subdirectories are created. The last respective extension of every file is replaced by .csts.
Input format. The input is plain Czech text in ISO 8859-2 encoding. Line break serves as a sentence separator (if we want to force the tool to separate them); double line break is a paragraph separator. The example of an input follows.
Asociace uvedla, že domácí poptávka v září stoupla o 8,8 %.
Output format. The output is a CSTS file with its header filled with default values. We recommend to alter them to true values bearing information about the source and the author of the text. The example output follows.
<csts lang=cs> <doc file="example.txt" id=1> <a> <mod>s <txtype>inf <genre>mix <med>nws <temp>2005 <authname>y <opus>example.txt <id>001 </a> <c> <p n=1> <s id="example.txt:001-p1s1"> <f cap>Asociace <f>uvedla <D> <d>, <f>že <f>domácí <f>poptávka <f>v <f>září <f>stoupla <f>o <w num.orig>8,8 <f num.gen>8.8 <d>% <D> <d>. </c> </doc> </csts>
The goal of morphological analysis is to assign all possible lemmas and morphological tags to word forms.
The base of the morphological analyzer is a large morphological dictionary containing now more than 350,000 entries. Every entry contains a stem, a paradigm with all endings appropriate for that stem together with morphological tags, and a lemma. On the basis of the current dictionary and the derivational module, the analyzer is able to recognize about 12 million of Czech word forms. The morphological analyzer works on word forms alone, it does not look around, at surrounding words.
Error rate. In average, 2.5% of all word forms are unrecognized, most of them are foreign proper names and typos.
Execution. The analyzer and the tagger are run together by the command
run_morphology input_directory output_directory
The files with .csts extension from the input directory are processed and copied into the output directory (it does not need to exist) under the same names.
Input format. CSTS produced by the segmentizer and tokenizer.
Output format. CSTS; since morphological analyzer and tagger perform their operation at once, the example output is postponed to the next section.
This stage, called disambiguation or tagging, consists in selecting a single pair lemma-tag from all possible alternatives assigned by the morphological analyzer. Tagging takes into account a short context of every word, including sentence boundaries. The tagger we provide is based on statistical methods.
Error rate. On evaluation test of PDT 2.0 (data/full/mw/etest), 93.08% of tags are assigned correctly.
Execution. Tagger is executed together with the morphological analyzer.
Input format. CSTS produced by the morphological analyzer.
Output format. CSTS; the disambiguated lemma is the content of MDl element, the disambiguated tag string is the content of MDt element. The example (only the content of element p, since the file header is not changed) follows. (For several tokens only a part of output of the analyzer and tokenizer is shown.)
<s id="example.txt:001-p1s1"> <f cap>Asociace<MDl src="a">asociace<MDt src="a">NNFS1-----A---- <MMl src="ad">asociace<MMt src="ad">NNFP1-----A---- <MMt src="ad">NNFP4-----A----<MMt src="ad">NNFP5-----A---- <MMt src="ad">NNFS1-----A----<MMt src="ad">NNFS2-----A---- <MMt src="ad">NNFS5-----A---- <f>uvedla<MDl src="a">uvést<MDt src="a">VpQW---XR-AA--- <MMl src="ad">uvést<MMt src="ad">VpQW---XR-AA--- <D> <d>,<MDl src="a">,<MDt src="a">Z:-------------<MMl src="ad">, <MMt src="ad">Z:------------- <f>že<MDl src="a">že<MDt src="a">J,-------------<MMl src="ad">že <MMt src="ad">J,------------- <f>domácí<MDl src="a">domácí<MDt src="a">AAFS1----1A---- <MMl src="ad">domácí<MMt src="ad">AAFP1----1A---- <MMt src="ad">AAFP4----1A----<MMt src="ad">AAFP5----1A---- <MMt src="ad">AAFS1----1A----<MMt src="ad">AAFS2----1A---- <f>poptávka<MDl src="a">poptávka<MDt src="a">NNFS1-----A---- <MMl src="ad">poptávka<MMt src="ad">NNFS1-----A---- <f>v<MDl src="a">v-1<MDt src="a">RR--6----------<MMl src="ad">v-1 <MMt src="ad">RR--4----------<MMt src="ad">RR--6---------- <f>září<MDl src="a">září<MDt src="a">NNNS6-----A----<MMl src="ad">zář <MMt src="ad">NNFP2-----A----<MMt src="ad">NNFS7-----A---- <MMl src="ad">září<MMt src="ad">NNNP1-----A---- <MMt src="ad">NNNP2-----A----<MMt src="ad">NNNP4-----A---- <f>stoupla<MDl src="a">stoupnout_:W<MDt src="a">VpQW---XR-AA--1 <MMl src="ad">stoupnout_:W<MMt src="ad">VpQW---XR-AA--1 <f>o<MDl src="a">o-1<MDt src="a">RR--4----------<MMl src="ad">o-1 <MMt src="ad">RR--4----------<MMt src="ad">RR--6---------- <w num.orig>8,8 <f num.gen>8.8<MDl src="a">8.8<MDt src="a">C=------------- <MMl src="ad">8.8<MMt src="ad">C=------------- <d>%<MDl src="a">%<MDt src="a">Z:------------- <MMl src="ad">%<MMt src="ad">Z:------------- <D> <d>.<MDl src="a">.<MDt src="a">Z:------------- <MMl src="ad">.<MMt src="ad">Z:-------------
To view the comprehensive list of publications on Czech tagging, visit the complete guide to Czech language tagging.
With the kind permission of the author, we distribute the Czech adaptation of the parser of Michael Collins. Unlike the usual approaches to the description of English syntax, the Czech syntactic descriptions are dependency-based, which means, that every edge of a syntactic tree captures relation of dependency between a governor and its dependent node. Collins' parser gives the most probable parse of a given input sentence. You can read the description of its Czech adaptation.
The first phase of parsing is preprocessing; in the course of which the output of morphological analysis (elements MMl and MMt) is removed and only the output of the tagger is retained.
Important
Since the parser can get jammed by parsing longer sentences, in this phase sentences longer than certain limit are removed. The limit is set to 60 words.
The parser cannot process more files at once and its initialization takes long time to be performed for every file separately, therefore a trick is used: before parsing, all the files are merged into one file, it is parsed, and the output file is split again.
Error rate. On development test data of PDT 2.0, 82.4% parents were assigned correctly. On evaluation test data, 81.6% parents were assigned correctly. Both training and test data were tagged machinely.
Execution. The parser is run by the command
run_parser input_directory output_directory
The files with .csts extension from the input directory are parsed and copied into the output directory (it does not need to exist) under the same names.
Input format. CSTS produced by the tagger.
Output format. CSTS; the assigned parent is stored in MDg element. The example (only content of element p) follows.
<s id="example.txt:001-p1s1"> <f cap>Asociace<MDl src="a">asociace<MDt src="a">NNFS1-----A----<r>1<MDg src="mcc">2 <f>uvedla<MDl src="a">uvést<MDt src="a">VpQW---XR-AA---<r>2<MDg src="mcc">0 <D> <d>,<MDl src="a">,<MDt src="a">Z:-------------<r>3<MDg src="mcc">4 <f>že<MDl src="a">že<MDt src="a">J,-------------<r>4<MDg src="mcc">2 <f>domácí<MDl src="a">domácí<MDt src="a">AAFS1----1A----<r>5<MDg src="mcc">6 <f>poptávka<MDl src="a">poptávka<MDt src="a">NNFS1-----A----<r>6<MDg src="mcc">9 <f>v<MDl src="a">v-1<MDt src="a">RR--6----------<r>7<MDg src="mcc">6 <f>září<MDl src="a">září<MDt src="a">NNNS6-----A----<r>8<MDg src="mcc">7 <f>stoupla<MDl src="a">stoupnout_:W<MDt src="a">VpQW---XR-AA--1<r>9<MDg src="mcc">4 <f>o<MDl src="a">o-1<MDt src="a">RR--4----------<r>10<MDg src="mcc">9 <w num.orig>8,8 <f num.gen>8.8<MDl src="a">8.8<MDt src="a">C=-------------<r>11<MDg src="mcc">10 <d>%<MDl src="a">%<MDt src="a">Z:-------------<r>12<MDg src="mcc">11 <D> <d>.<MDl src="a">.<MDt src="a">Z:-------------<r>13<MDg src="mcc">0
To view the comprehensive list of publications on the Czech parsing, visit a complete guide to Czech language parsing.
In our implementation, the automatic assignment of analytical functions (afuns) to nodes in an analytical tree is seen as a classification task (each node gets one afun) and is solved using a decision tree approach. The decision tree for assigning afuns was induced from the PDT 1.0 training data by Quinlan's C5 classifier and then automatically translated to Perl. The features used in the decision tree are mostly extracted from the morphological tag of the node itself and of its parent's node.
For the proper function of the automatic assigner, btred has to be installed, since the assigner is written as a TrEd/btred's macro.
Error rate. Precision of the system (measured on the unseen test data as the number of correctly assigned functions divided by the number of all analytical nodes) is around 92%.
Execution. The assigner is run by the command
run_afun input_directory output_directory
The files with .csts extension from the input directory are processed and copied into the output directory (it does not need to exist) under the same names.
Input format. CSTS produced by the parser.
Output format. CSTS; the assigned analytical function is the content of the MDA element. The example (only the content of the element p) follows.
<s id="example.txt:001-p1s1"> <f cap>Asociace<MDl src="a">asociace<MDt src="a">NNFS1-----A----<MDA src="c5_zz">Sb<r>1<MDg src="mcc">2 <f>uvedla<MDl src="a">uvést<MDt src="a">VpQW---XR-AA---<MDA src="c5_zz">Pred<r>2<MDg src="mcc">0 <D> <d>,<MDl src="a">,<MDt src="a">Z:-------------<MDA src="c5_zz">AuxX<r>3<MDg src="mcc">4 <f>že<MDl src="a">že<MDt src="a">J,-------------<MDA src="c5_zz">AuxC<r>4<MDg src="mcc">2 <f>domácí<MDl src="a">domácí<MDt src="a">AAFS1----1A----<MDA src="c5_zz">Atr<r>5<MDg src="mcc">6 <f>poptávka<MDl src="a">poptávka<MDt src="a">NNFS1-----A----<MDA src="c5_zz">Sb<r>6<MDg src="mcc">9 <f>v<MDl src="a">v-1<MDt src="a">RR--6----------<MDA src="c5_zz">AuxP<r>7<MDg src="mcc">6 <f>září<MDl src="a">září<MDt src="a">NNNS6-----A----<MDA src="c5_zz">Atr<r>8<MDg src="mcc">7 <f>stoupla<MDl src="a">stoupnout_:W<MDt src="a">VpQW---XR-AA--1<MDA src="c5_zz">Adv<r>9<MDg src="mcc">4 <f>o<MDl src="a">o-1<MDt src="a">RR--4----------<MDA src="c5_zz">AuxP<r>10<MDg src="mcc">9 <w num.orig>8,8 <f num.gen>8.8<MDl src="a">8.8<MDt src="a">C=-------------<MDA src="c5_zz">Adv<r>11<MDg src="mcc">10 <d>%<MDl src="a">%<MDt src="a">Z:-------------<MDA src="c5_zz">AuxG<r>12<MDg src="mcc">11 <D> <d>.<MDl src="a">.<MDt src="a">Z:-------------<MDA src="c5_zz">AuxK<r>13<MDg src="mcc">0
The last step of machine annotation is conversion of the resulting file(s) into PML data format. You also can read more about conversion into PML.
For the proper function of the converter, TrEd has to be installed, since the converter is written as a TrEd's macro.
Execution. The converter is run by the command
run_pml_converter input_directory output_directory
The files with .csts extension from the input directory are processed and copied into the output directory (it does not need to exist): for every file three files with the same name and extensions .w.gz, .m.gz, and .a.gz are created.
Input format. CSTS
Output format. gzipped PML
Note. If you want to view the processed data in CSTS format with TrEd and want them to look similarly as on the Figure 1, "Visualized example sentence processed by the supplied tools", there are a few steps to be performed, since TrEd expects human-made annotation in CSTS files by default. Namely you should execute TrEd with -X govMD_mcc,ord option. Furthemore you should create a new stylesheet by <New From Current> option in the menu in the upper right corner of TrEd's window and change node: ${afun} into node: ${afunMD_c5_zz} in it by Edit stylesheet... in View menu. With data in PML format, no such an action need to be performed.
Execution. All the tools can be run at once by the command
run_all output_directory filepath(s)
The given directory and its five subdirectories are created: 1-token, 2-morph, 3-pars, 4-afuns, and 5-pml, which the files created at respective stages of processing are saved into. The directory does not need to exist. The given path(s) describes files to be processed. The last possible extension of every file, with the exception of the last tool, is replaced with .csts.
Input format. See input format in Section 1, "Segmentation and tokenization".
Output format. CSTS
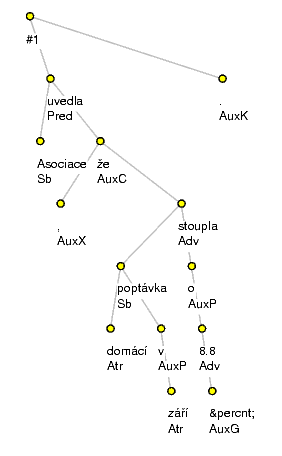
On the Figure 1, "Visualized example sentence processed by the supplied tools" we can see that the parser made some mistakes: prepositional phrase v září (in September) should depend on stoupla (rose) rather than on poptávka (demand). Moreover, nodes 8.8 and % are swapped.