Table of Contents
The data is the only part of PDT 2.0 distribution which cannot be viewed on the website of PDT, http://ufal.mff.cuni.cz/pdt2.0/. The only downloadable parts of the data are sample data (see Section 3.7, "Sample data") and PDT-vallex (see Section 3.8, "PDT-VALLEX"). If you wish to obtain also the full data (see Section 3.6, "Full data") and PDT 1.0 update (see Section 3.9, "PDT 1.0 update"), you have to get the distribution CD-ROM-Chapter 7, Distribution and license describes how to do it.
The data are located in the directory data.
The data in Prague Dependency Treebank are annotated articles (non-abbreviated) from the following newspapers and journals:
- Lidové noviny (daily newspapers), ISSN 1213-1385, 1991, 1994, 1995
- Mladá fronta Dnes (daily newspapers), 1992
- Českomoravský Profit (business weekly), 1994
- Vesmír (scientific journal), ISSN 1214-4029, Vesmír, s.r.o., 1992, 1993
The amount of data from the particular sources is given in Figure 3.1, "Number of tokens from the particular sources".
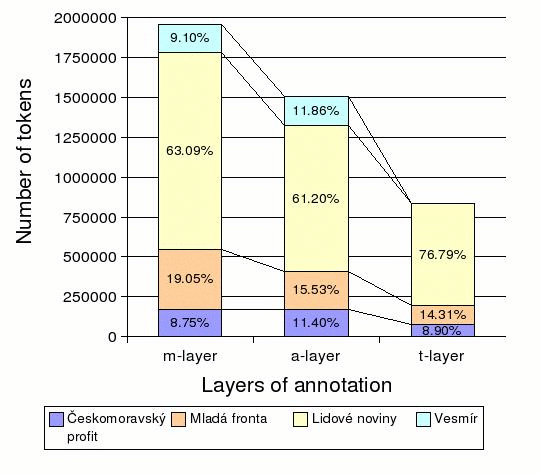
The texts in electronic form have been provided by the Institute of the Czech National Corpus. The texts came from their providers in several formats. Sometimes original formating has been preserved but in general only the division to documents (articles) and paragraphs has been adopted.
For various reasons (mostly just mistakes), the original data contained duplicates. When a duplicity was longer than three sentences, it has been removed. Further, very high frequency non-word data like over-typings of chess games, tables with results of sport matches etc. have almost all been removed with a few kept to remind us of their existence and to show a suggested (rather technical) annotation scheme for them.
Annotations of the particular layers do not cover the data equally. The more complex a layer is, the less data have been annotated at it. The reason is obvious-annotation of a more complex layer needs more time, resources, and human work; there are other technological considerations as well (e.g., for a certain setup of higher-layer tool development, there must be more data available for training purposes on the lower layer the annotation of which cannot be used at the upper layer anyway). Any file annotated at a certain layer is annotated also at all the simpler ones. See Figure 3.2, "Division of the data to layers" for an illustration.
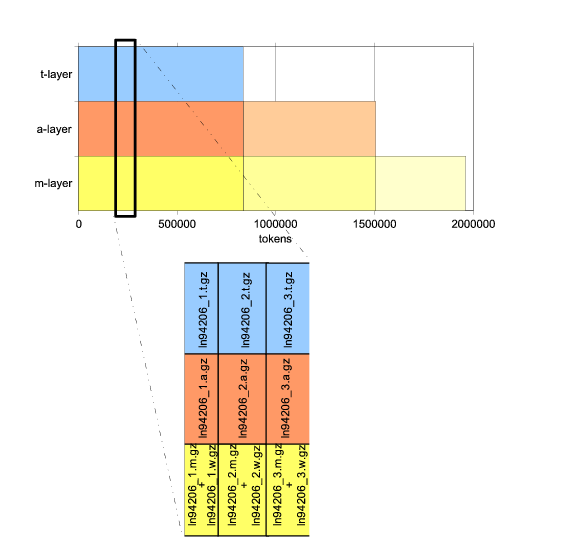
For details on layers, see Chapter 2, Layers of annotation. For details on reflecting layers of annotation in names of files, see Section 3.5, "Conventions of file naming". For details on data quantities, see Section 3.6, "Full data".
As usual, the data are divided into three groups: the training data, the development test data and the evaluation test data. The training data cover approximately 80%, development 10% and evaluation 10% of the whole set of data (these proportions hold for all the three layers of annotation).
The users can freely exploit the training set and test their hypotheses or tools on the development test data. Evaluation test data should be never looked into, they are intended for evaluation and reporting purposes only. Moreover, the evaluation data should be used advisedly and as rarely as possible, since the observations gained from the repeated tests on the evaluation data could lead to a change of the original hypothesis/tool and thus the evaluation data would start functioning as the training data.
Although the train/dtest/etest proportion is roughly the same as in PDT 1.0 (8:1:1), the old division has not been preserved due to several reasons. The data in PDT 2.0 were divided in the following way: documents of the morphological layer were read in sequence and cyclically distributed, the first one was folded into train-1 set, second one into train-2, and so on to train-8, the ninth to dtest and tenth to etest. Eleventh document went to train-1 again etc. (Training set was divided into eight subsets to lower the number of files in directories but the existence of ten equally large sets of data might serve in cross-validation experiments as well.) Documents annotated on the other layers went together with their morphologically annotated versions. Since the documents for annotation were selected sequentially, the algorithm guarantees that the proportions remain almost the same (8:1:1), with only a small deviation due to differences in the size of the documents.
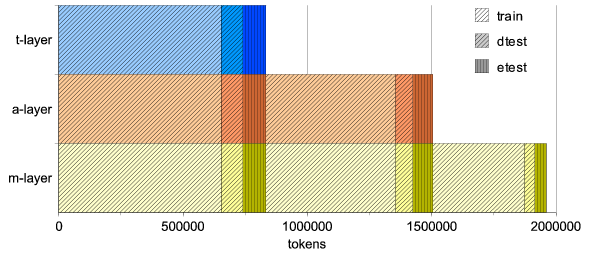
Figure 3.3, "Division of the data into training and test sets" shows the division of the data. Note that the algorithm makes sure that every file belongs to the same set (training vs. development test vs. evaluation test) on all the layers it has been annotated at. (For details on data quantities, see Section 3.6, "Full data".)
It should be noted that if the user performs for instance an experiment on a-layer data and the experiment has nothing to do with t-layer, then s/he should use such division of the data which disregards the fact whether the document in question is annotated on t-layer or not. As a result, e.g. etest subset of the a-layer data is in fact composed of two parts, as it is visible in Figure 3.3, "Division of the data into training and test sets" (two vertically shaded areas in the middle row). By analogy, train-1 subset of the m-layer data is composed of three parts. The issues related to such groupings are also addressed in Section 3.6, "Full data".
The primary data format for PDT 2.0 is an XML-based format called PML. Historically, two other formats have been developed and used for processing and storage of PDT data. The FS format has been developed for Netgraph program (strictly speaking, for its ancestor, Graph program). A SGML-based format, called CSTS, has been the primary format of PDT 1.0. It is now used only as an intermediate format in older NLP tools (such as taggers and parsers).
For information on conversion between these formats, see Section 4.4.1, "Conversion between the PDT formats".
PML ("Prague Markup Language"), is a generic XML-based data format designed for the representation of rich linguistic annotation of text, such as morphological tagging, dependency trees, etc. PML is an on-going project in its early stage. Yet, enough has already been developed to allow an adequate and straightforward representation of the PDT 2.0 data. In the following text, we give a brief summary of PML main features. A detailed information about PML as a generic format can be found in the PML documentation. An overview of how PDT 2.0 data are actually represented in PML can be found in the PDT 2.0 Annotation Markup Reference.
In PML, individual layers of annotation can be stacked one over another in a stand-off fashion and linked together as well as with other data resources in a consistent way. Each layer of annotation is described in a PML schema file, which could be imagined as a formalization of an abstract annotation scheme for the particular layer of annotation. In brief, the PML schema file describes which elements occur on that layer, how they are nested and structured, of which types the values occurring in them are, and what role they play in the annotation scheme (this PML-role information can also be used by applications to determine an adequate way to present a PML instance to the user). Other formal schemata such as Relax NG can be automatically generated from a PML schema, so that formal consistency of PML-schema instances could be verified using conventional XML-oriented tools (a XSLT stylesheet providing conversion of PML schema to Relax NG is available in tools/pml/pml2rng.xsl).
Every PML instance starts with a header where a PML schema is associated with the instance and where all external resources which the instance points to are listed, together with some additional information necessary for correct link resolving. The rest of the instance is dedicated to the annotation itself.
The annotation is expressed by means of XML elements and attributes, named and nested according to the associated PML schema. XML elements of a PML instance occupy a dedicated namespace http://ufal.mff.cuni.cz/pdt/pml/. PML format offers unified representations for the most common annotation constructs, such as attribute-value structures, lists or alternatives of values of a certain type (either atomic or further structured), references within a PML instance, links among various PML instances (used in PDT 2.0 to create links across layers) or to other external XML-based resources. At the moment, PML also offers a limited support for XML mixed content. To avoid confusion with XML attributes, we usually refer to attributes of an attribute-value structure as members.
PDT 2.0 contains annotation divided into up to four layers stacked one upon another, namely the word, morphological, analytical, and tectogrammatical layers (see Chapter 2, Layers of annotation). Each of the layers defines its own PML schema.
Tectogrammatical and analytical trees are represented in PML commonly as nested attribute-value structures. In this representation, a node is realized as an attribute-value structure with PML-role #NODE. Each node has a dedicated member with a PML-role #CHILDNODES, which contains a list of child-nodes of the node. Because of the auxiliary character of root nodes of the dependency trees of PDT 2.0, the structure representing the technical root of the tree is of a type different from the rest of the nodes (i.e. has a different set of members).
See also the PDT 2.0 Annotation Markup Reference for a comprehensive overview of the PML representation of the four annotation layers. PML and Relax NG schemata for the four layers can be found in the directory data/schemas.
When working with PML, which is the XML-based primary format of PDT 2.0, the tools based on Perl such as TrEd and btred parse the original XML and build their internal memory representation. This transformation is time consuming, but can be completely avoided when working with the pls.gz data format (Perl Storable Format). It is a binary format which directly mirrors the internal memory representation and thus is much faster to store and load. But on the other hand, this format has nothing to do with XML any more and is hardly processible by other tools.
The FS ("feature structure") file format is a generic format for representation of trees whose nodes are attribute-value structures. It can be viewed as a "meta-format", similarly to SGML or XML. An application of this format is fully specified by attribute declarations in a FS-file header (thus with respect to FS format, the header of an FS-file plays a similar role to that of DTD with respect to a particular application of SGML).
Every FS-file starts with a declaration of its attributes. In general, each line of the declaration consists of @-character, property of the attribute, a space, and name of that attribute. E.g. property O means "obligatory", i.e. values of such an attribute must be non-empty for every node; or property L, "list", requires that the attribute value (if not empty) is one of those listed in a |-separated list following the attribute name. The complete description can be found in the FS format specification.
The declaration header ends with an empty line and it is followed by descriptions of trees representing the annotation. Every tree description starts on a new line. Trees are described in a usual parentheses notation, i.e. after the description of a node the list of its child-nodes enclosed in parentheses follows. Descriptions of individual child-nodes are separated by commas. Description of every node is enclosed in square brackets and consists of comma-separated list of attribute=valueP, "positional", it can be given only by its value and its name is derived as the name of the first positional attribute whose definition in the header follows the definition of the last attribute in the list (or the first positional attribute if the value is the first attribute description occurring in the list).
CSTS ("Czech sentence tree structure") is an application of SGML. CSTS has been the primary format for PDT 1.0 and in spite the fact that in PDT 2.0 it has been superseded by PML, some tools still depend on it. CSTS can only represent morphological and analytical annotation (to be precise, its definition contains also some elements related to tectogrammatical annotation, but it is not capable of fully capturing the t-layer of PDT 2.0). Wherever possible, we highly recommend using PML (see Section 3.4.1, "PML") instead-this applies especially to any new tools. For more details, see complete description of CSTS and its DTD file.
The data of PDT 2.0 are distributed in the PML format (see its description in Section 3.4.1, "PML"). Each data file relates to one annotated document-the base of its name is the identifier of the document (and it indicates the source of the document, see Section 3.1, "Sources of text": ln* denotes Lidové noviny, mf* denotes Mladá fronta Dnes, vesm* denotes Vesmír, and cmpr* denotes Českomoravský profit). The extension of the file expresses the layer of annotation of the document (.w denotes w-layer, .m denotes m-layer, .a denotes a-layer, and .t denotes t-layer). (See the description of the layers in Chapter 2, Layers of annotation.)
Every file with annotation of a document at some layer relates one-to-one to files with its lower-layer annotations and contains links into them. This is the reason why the files should not be renamed. Links from lower layers to higher layers of annotation do not exist. For an overview of layer linking, see also Figure 2.1, "Linking the layers".
For example, cmpr9406_001.a.gz denotes (gzipped) file with a-layer of annotation of document cmpr9406_001 (originating from Českomoravský profit). It contains links into files cmpr9406_001.m.gz and cmpr9406_001.w.gz; however, it says nothing about the existence of file cmpr9406_001.t.gz.
Whether a file is a part of the training set or the test one etc. is not captured in its name but with its place in a directory structure, see Section 3.3, "Division of the data into training and test sets".
Names of identifiers of sentences and tokens are derived from the name of the file they occur in. Every identifier is unique in the whole treebank.
The full version of the PDT 2.0 data is available to the licensed users who obtained CD-ROM PDT 2.0 from Linguistic Data Consortium (see Chapter 7, Distribution and license). Small data sample can also be downloaded from the web (see Section 3.7, "Sample data").
The full version of the PDT 2.0 data consists of 7,110 manually annotated textual documents, containing altogether 115,844 sentences with 1,957,247 tokens (word forms and punctuation marks). All these documents are annotated on the m-layer. 75% of the m-layer data are annotated on the a-layer (5,330 docs., 87,913 sents., 1,503,739 toks.). 59% of the a-layer data are annotated also on the t-layer (i.e. 45% of the m-layer data; 3,165 docs., 49,431 sents., 833,195 toks.).
The full data are located in the directory data/full on the CD-ROM PDT 2.0. (In parallel, the full data annotated at least on the a-layer are-merely for the benefit of faster processing by TrEd-based tools-converted also into the binary Perl Storable Format; the converted files are to be found in the directories data/binary/amw and data/binary/tamw.) The data files are divided according to the following two-level hierarchy:
-
The primary branching corresponds to the highest layer of annotation (see Chapter 2, Layers of annotation) available for the document in question:
-
data/full/tamw/- documents annotated on all three layers, -
data/full/amw/- documents annotated only on the m-layer and a-layer, -
data/full/mw/- documents annotated only on the m-layer.
-
-
Then, the content of each of these three directories is further split into ten parts of roughly equal size (see Section 3.3, "Division of the data into training and test sets"). Eight of them are to be used for training purposes (from
train-1/totrain-8/), one for development tests (dtest/) and one for evaluation tests (etest/).
Even if the data files are distributed into as many as thirty directories, the amount of files in individual directories still remains large. This is partially due to the fact that the number of physical files (compared to the number of the original textual documents) is multiplied by the factor of four in case of tamw data (for each document, there are four files containing its annotation on respective layer stored in the same directory, see Section 3.5, "Conventions of file naming"), by three in amw, and by two in mw. Thus the total number of data files is 4 x 3165 + 3 x 2165 + 2 x 1780 = 22715. For instance, the directory data/full/tamw/train-3/ contains 4 x 317 = 1,268 data files.
Note that no data file occurs twice in data/full/ (e.g., the *.m files from data/full/amw/ do not appear again in data/full/mw/). All the thirty subdirectories have mutually disjoint contents, as they contain annotations of different texts.
Detailed quantitative properties of the data distributed according to the above principles are presented in Table 3.1, " Data annotated on all three layers (tamw). ", Table 3.2, " Data annotated only on m-layer and a-layer (amw). ", and Table 3.3, " Data annotated only on m-layer (mw). ".
Table 3.1. Data annotated on all three layers (tamw).
tamw |
train | dtest | etest | total |
|---|---|---|---|---|
| Location on the CD-ROM |
... |
tamw/dtest/ |
tamw/etest/ |
tamw/*/ |
|
# documents |
2,533 ( 80.0 %) |
316 ( 10.0 %) |
316 ( 10.0 %) |
3,165 ( 100.0 %) |
|
# sentences |
38,727 ( 78.3 %) |
5,228 ( 10.6 %) |
5,476 ( 11.1 %) |
49,431 ( 100.0 %) |
|
# tokens |
652,544 ( 78.3 %) |
87,988 ( 10.6 %) |
92,663 ( 11.1 %) |
833,195 ( 100.0 %) |
Table 3.2. Data annotated only on m-layer and a-layer (amw).
amw |
train | dtest | etest | total |
|---|---|---|---|---|
| Location on the CD-ROM |
... |
amw/dtest/ |
amw/etest/ |
amw/*/ |
|
# documents |
1,731 ( 80.0 %) |
217 ( 10.0 %) |
217 ( 10.0 %) |
2,165 ( 100.0 %) |
|
# sentences |
29,768 ( 77.4 %) |
4,042 ( 10.5 %) |
4,672 ( 12.1 %) |
38,482 ( 100.0 %) |
|
# tokens |
518,647 ( 77.3 %) |
70,974 ( 10.6 %) |
80,923 ( 12.1 %) |
670,544 ( 100.0 %) |
Table 3.3. Data annotated only on m-layer (mw).
mw |
train | dtest | etest | total |
|---|---|---|---|---|
| Location on the CD-ROM |
... |
mw/dtest/ |
mw/etest/ |
mw/*/ |
|
# documents |
1,422 ( 79.9 %) |
179 ( 10.1 %) |
179 ( 10.1 %) |
1,780 ( 100.0 %) |
|
# sentences |
22,333 ( 80.0 %) |
2,610 ( 9.3 %) |
2,988 ( 10.7 %) |
27,931 ( 100.0 %) |
|
# tokens |
364,640 ( 80.4 %) |
42,689 ( 9.4 %) |
46,179 ( 10.2 %) |
453,508 ( 100.0 %) |
Those who want to work only with the m-layer or a-layer data no matter whether the documents are annotated also on the higher layer(s) or not should use alternative groupings. For instance, when experimenting with all the m-layer data, the training data should consist of all of data/full/{tamw,amw,mw}/train-[1-8]/*m.gz files.
Numbers of all documents annotated on the m-layer (no matter whether a-layer and t-layer annotations exist) are merged in Table 3.4, " Alternative grouping: All data annotated on m-layer (union of tamw, amw, and mw). ". All documents annotated on the a-layer (no matter whether t-layer annotation exists) are merged in Table 3.5, " Alternative grouping: All data annotated on a-layer (union of tamw and amw). ".
Table 3.4. Alternative grouping: All data annotated on m-layer (union of tamw, amw, and mw).
all_m |
train | dtest | etest | total |
|---|---|---|---|---|
| Location on the CD-ROM |
...
|
*/dtest/ |
*/etest/ |
*/*/ |
|
# documents |
5,686 ( 80.0 %) |
712 ( 10.0 %) |
712 ( 10.0 %) |
7,110 ( 100.0 %) |
|
# sentences |
90,828 ( 78.4 %) |
11,880 ( 10.3 %) |
13,136 ( 11.3 %) |
115,844 ( 100.0 %) |
|
# tokens |
1,535,831 ( 78.5 %) |
201,651 ( 10.3 %) |
219,765 ( 11.2 %) |
1,957,247 ( 100.0 %) |
Table 3.5. Alternative grouping: All data annotated on a-layer (union of tamw and amw).
all_a |
train | dtest | etest | total |
|---|---|---|---|---|
| Location on the CD-ROM |
...
|
*a*/dtest/ |
*a*/etest/ |
*a*/*/ |
|
# documents |
4,264 ( 80.0 %) |
533 ( 10.0 %) |
533 ( 10.0 %) |
5,330 ( 100.0 %) |
|
# sentences |
68,495 ( 77.9 %) |
9,270 ( 10.5 %) |
10,148 ( 11.5 %) |
87,913 ( 100.0 %) |
|
# tokens |
1,171,191 ( 77.9 %) |
158,962 ( 10.6 %) |
173,586 ( 11.5 %) |
1,503,739 ( 100.0 %) |
Needless to say that any published experiment performed on the PDT 2.0 data should be accompanied with the information specifying which part of the data was used (for which purpose) in the experiment.
In order to facilitate the work with the large number of data files, we provide the user with pre-generated file lists located as separate files in the directory data/filelists/; not only they are useful when working in tred/btred/ntred environment, but the file-list style of work avoids the problems related to having too many arguments on a command line. However, only a few basic file lists are given, since it is not difficult for the user to create a new file list corresponding to any desired subset of the full data (see also btred/ntred tutorial).
A small portion of the full data is also available from the website for download (again, how to order the full version see in Chapter 7, Distribution and license). The data are divided into ten groups (sample0 to sample9) of approximately 50 sentences each. Each group consists of four files (sampleX.w.gz, sampleX.m.gz, sampleX.a.gz, and sampleX.t.gz); the extension of a file expresses that the file contains annotation of a sample at the respective layer (see Section 3.5, "Conventions of file naming"). Sample data are randomly selected segments of the full data (see Section 3.6, "Full data").
The sample data are stored in the directory data/sample. In the same directory, there also is the archive of all the sample files. If you cannot or do not want to install a tool that can deal with the data in PML format (see Chapter 4, Tools), you might wish to view all the sample data as web-pages.
PDT 2.0 contains a limited lexical semantic annotation that links the underlying and surface syntax and morphology in a novel way by means of a valency dictionary, called PDT-VALLEX. It is stored in the directory data/pdt-vallex in an XML format (see its description) or can be browsed as web-pages-see visualization of its sample entry in Figure 3.4, "PDT-VALLEX sample entry in the presentation format". The entry dosáhnout (to reach) has the following frames: (1) to reach (a certain level), (2) to make sbd. promise sth., (3) to achieve one's goal, (4) to reach (up to sth.).

Entries of PDT-VALLEX contain individual senses of verbs and certain verbal nouns and adjectives that have been found in the corpus. Each sense contains a valency frame with semantic, syntactic and morphological information about its semantically obligatory and/or optional dependents.
Every valency frame contains zero or more valency slots. Each slot has a syntactic or semantic label (such as ACT, PAT, ADDR, LOC, AIM, CRIT, BEN etc.; for more about the tectogrammatical annotation in general, see Tectogrammatical Annotation of the PDT: Annotator's Guidelines), and it is marked either as obligatory or optional. In addition, the slots contain surface syntactic and morphological information about their surface realization (expression), such as morphological case, or preposition to be used with the corresponding lexical unit, or, in the case of phrasal expressions, a whole syntactic subtree that forms the phrase on the surface.
The most important feature of PDT-VALLEX is, however, the fact that every occurrence of a verb and a verbal noun in PDT 2.0 is linked (using a special sentence node attribute of a reference type) from the corpus to the dictionary entry, effectively creating a disambiguated word sense annotation for these words. The labels, optionality/obligatoriness, and surface morphological form(s) of the entry being pointed to from the corpus have been fully checked against the data annotation at all three layers, as appropriate.
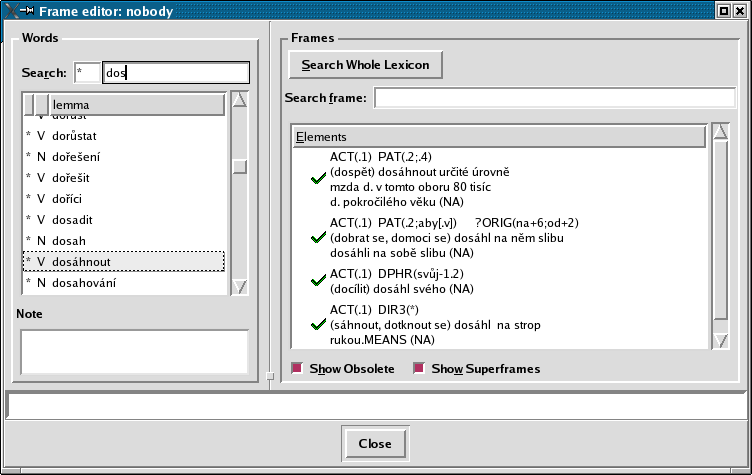
Tools allowing to take advantage of the links between the corpus and the dictionary (simultaneous browsing, searching and editing by the TrEd editor-see Figure 3.5, "PDT-VALLEX in the TrEd editor") are provided.
Although the main difference between PDT 1.0 and PDT 2.0 is the presence of the annotation on the tectogrammatical layer (see Section 2.3, "Tectogrammatical layer"), many changes have been done on the lower layers, too. For the users of PDT 1.0 we provide the data update that adds all the changed and new information to the original data. The update resides in the directory data/pdt1.0-update. The patch is restricted to the CSTS format only, old FS files cannot be updated.
The changes include:
- corrections of various errors on morphological and analytical layer,
- corrections of spelling errors,
- added human morphological annotation to all files.
Requirements for applying the patch. To update the data, you need two GNU tools, gunzip and patch. On Linux, these tools are usually already installed. On Windows, please download GNU patch (other versions of it might not work). gunzip on Windows seems to work both from the Cygwin distribution as well as from GNU. PDT 2.0 CD-ROM contains a copy of Cygwin gunzip.exe in the directory tools/tred/bin/, so you can simply use that one.
Applying the patch to all data directories. PDT 1.0 CD-ROM contains several overlapping (by means of hard-links) subsets of the data in subdirectories of the directory PDT_1.0_CD-ROM/Corpora/PDT_1.0/Data/fs/ and fs-am/ have to be patched. On Linux, a script that patches all the subdirectories at once is available in data/pdt1.0-update/linux-apply-patch.sh. Run the script and follow the instructions. On Windows, we cannot provide a secure means to automatically apply the patch to all data directories. Please follow the instructions below and apply the patch manually to all the data subdirectories you need.
Applying the patch to a single data directory.
- Copy files in a subdirectory of
Corpora/PDT_1.0/Data/(except forfs/andfs-am/) on the PDT 1.0 CD-ROM to a new working directory. - Switch to this directory: cd
the_working_directory - Gunzip all the files: gunzip *.gz
-
Apply the patch: gunzip -c
PDT_2.0_CD-ROM/data/pdt1.0-update/pdtpatch.gz | patch -p1 -tThe
-tflag is required when patching incomplete directories, i.e. directories that do not contain all PDT 1.0 data files. This flag instructspatchto skip missing files without prompting the user. On Windows, make sure to add the flag--binaryto the patch command. Otherwise, patching the files might fail.