Programování 1
-
přednáší Martin Pergel ve středu 17:20
- obsah přednášek: https://kam.mff.cuni.cz/~perm/programovani/NNPRG030/
-
cvičí Rudolf Rosa v pondělí 16:30-18:00 v N8
- cvičení pro kruh 37 paralelky X bakalářských studentů informatiky
-
navazuje na cvičení Algoritmizace 1 s Jiřím Šejnohou 15:40-16:25 v N8
- cvičení Programování a Algoritmizace jsou svázaná, navštěvujte tedy na sebe navazující cvičení!
- cvičení pro pokročilé má Martin Mareš v úterý (9:50-12:10 v N2)
Kdykoliv cokoliv potřebujete, napište mi na rosa@ufal.mff.cuni.cz (nebo mě oslovte po cvičení). Budu rád, když předmět e-mailu bude mimo jiné obsahovat kód předmětu (NPRG030), mám na to nastavené e-mailové filtry.
Obsah této stránky
- Konzultace
- Cvičení (materiály k jednotlivým cvičením)
- Pokyny
- Požadavky na zápočet (včetně informací o zápočtovém testu)
- Domácí úkoly
- Zápočtové programy
- Další informace
Konzultace
-
cvičení budou doplňovat interaktivní konzultace
- pravidelné konzultace během semestru jsou každé pondělí v N8 18:00-18:30 (tedy hned po cvičení, na stejném místě)
- individuální konzultace si se mnou domlouvejte podle potřeby (napiště mi e-mail)
-
konzultace je pro vás, je to ideální příležitost, když s něčím potřebujete poradit nebo pomoct, například:
- napsal jsem tenhle kus kódu a nefunguje to, proč?
- něčemu jsem na cvičení nerozuměl a chtěl bych to vysvětlit znova a lépe
- mám dotaz k něčemu ze cvičení nebo z přednášky
- mám dotaz k něčemu co nebylo na cvičení ani přednášce
- nerozumím zadání domácího úkolu
- rozumím zadání domácího úkolu, ale potřebuju poradit, jak ho řešit
- mám nějakou nejasnost/otázku/problém týkající se mého studia (ne nutně předmětu Programování 1)
- atd.
- jednak budu vyhlašovat hromadné konzultace, které se můžete účastnit všichni
-
jednak si budeme dle potřeby domlouvat soukromé konzultace
- napište mi mail, pokud se chcete domluvit na konzultaci
- některým z vás občas nabídnu konzultace i sám, třeba když si všimnu, že zjevně máte nějaké problémy -- ale raději se ozvěte sami, ne vždy si ne všeho všimnu
Cvičení 2022/2023
- 3.10. hello world (sčítání, násobení, input)
- 10.10. if (BMI)
- 17.10. while (Colatz, ZOO)
- 24.10. for (ZOO v listu)
- 31.10. funkce a sort (umocni, najdi minimum)
- 7.11. třídy a spojáky (tichá pošta)
- 14.11. spojáky (oranžový expres)
- 21.11. čtení souborů, zapisování do souborů, dict (zase BMI)
- 28.11. rekurze (zaplacení částky mincemi)
- 5.12. prohledávání do hloubky a do šířky
- 12.12. co se nestihlo (defaultdict, list comprehension, set, výjimky, moduly a importy)
- 19.12. testování (unit testy), grafika
3.10.
- přihlášení k počítači
- vzájemné seznámení
- Hello world
-
programování v Pythonu přímo v prohlížeči snadno a rychle
-
https://colab.research.google.com/
- je potřeba se přihlásit Google účtem
-
https://www.kaggle.com/kernels
- tady to jde i bez přihlášení
- NEW NOTEBOOK
-
print("Ahoj, jsem ptakopysk!") - kliknout na (►) nebo stisknout Shift+Enter
-
https://colab.research.google.com/
-
pár jednoduchých věcí na úvod
-
5+6
-
3*7
-
8-2
-
1/3
-
5*"ptakopysk"
-
"ptakopysk" + "podivný"
-
a=5
-
b=6
-
a+b
-
zvire="ptakopysk"
-
zvire=input()
-
- Visual Studio Code: https://code.visualstudio.com/
-
- tutoriál například zde: https://www.youtube.com/watch?v=WPqXP_kLzpo
- (ale klidně používejte jakýkoliv jiný editor)
- podmínky na zápočet: domácí úkoly, závěrečný test, zápočtový program
- konzultace
-
komunikační kanály
- e-mail rosa@ufal.mff.cuni.cz
- SIS
- Recodex
-
(v případě zájmu jiné kanály)
- (máte pro svůj ročník/kruh nějakou diskuzní skupinu? Facebook/Discord/?)
-
Recodex
- https://recodex.mff.cuni.cz/
- skupina
- první (a druhý) domácí úkol
10.10.
-
K úkolům
- pozor na Recodex, je přísný!
-
na přednášce bylo(?)
-
print, input
- to už jsme cvičili posledně
-
print(a, b, c, sep="_", endl="!!!\n")
-
f stringy?
-
text = f"Ahoj, já jsem {jmeno}, kdo jsi ty?"
-
- krokování asi nebylo? ale to si stejně zkusíme
-
print, input
-
na přednášce snad bude(??)
- int, float, str
- if-elif-else
- while
- ale pocvičíme to už dneska (while možná nestihneme)
-
zdvojovadlo: zeptá se uživatele na (celé) číslo, vypíše jeho dvojnásobek
-
ze vstupu dostanu string (textový řetězec), na číslo ho přetypuju takto:
-
cislo = int(text)
-
-
ze vstupu dostanu string (textový řetězec), na číslo ho přetypuju takto:
-
- úprava: pro kladné číslo vypíše jeho dvojnásobek, pro záporné číslo vypíše jeho trojnásobek
-
umocňovadlo: zeptá se uživatele na (celé) číslo, vypíše jeho druhou mocninu
- úprava: pro kladné číslo vypíše jeho druhou mocninu, pro záporné číslo vypíše jeho třetí mocninu
- zkusit si krokovat program ve VS Code
-
interaktivní výpočet BMI (souvisí s domácím úkolem)
-
-
napište jednoduchý program
-
program se zeptá uživatele na vstup, a to na jeho hmotnost (v kilogramech) a výšku (v metrech)
-
vypočítejte uživatelovo BMI, dle vzorečku hmotnost / výška2
-
vypište, zda má uživatel váhu v pořádku, či zda má podváhu či nadváhu
-
normální váha je při BMI 18.5 až 25, méně je podváha, více je nadváha
-
volitelně: vypište podrobnější hodnocení
-
volitelně: řekněte uživateli, jaké je pro jeho výšku rozmezí ideální váhy (např. od 85.7 kg to 98.2 kg)
-
volitelně: se znalostí průměrné hustoty lidského těla (1000 kg/m3) odhadněte objem uživatele, a spočítejte například, jaký by měl uživatel průměr a obvod, pokud by měl stejnou výšku ale tvar válce, případně jaký by měl průměr a obvod, pokud by měl tvar koule
-
-
-
na přednášce snad bylo
- while
- seznam (list) -- to možná procvičíme až příště, uvidíme
- program: uživatele se na nic neptá, vypíše druhé mocniny čísel od 1 do 20
-
hra: počítač si myslí číslo, uživatel ho hádá
-
import random
-
cislo = random.randint(0, 20)
- uživatel hádá, dokud se netrefí, jinak program řekne, jestli to bylo moc nebo málo
-
-
zkusit si pustit program v terminálu, nezávisle na VS Code
- Windows terminál: Win+R, cmd, Enter
- Linux terminál: Ctrl+Alt+T
-
potřeba pomocí cd přejít do správného adresáře
- cd C:\Nějaká\Cesta\Ke skriptům
- např. "cd Documents", pokud si kódy ukládáte do dokumentů
- možná taky "cd OneDrive\Documents" pokud Vaše dokumenty jsou ve skutečnosti OneDrive dokumenty
-
pak to nejspíš bude něco takového (na labových Windows jsme zjistili, že "python" spustí Python verze 2 a "py" spustí Python verze 3, takže chceme "py"):
-
py muj_program.py
-
python3 muj_program.py
-
-
Collatz conjecture
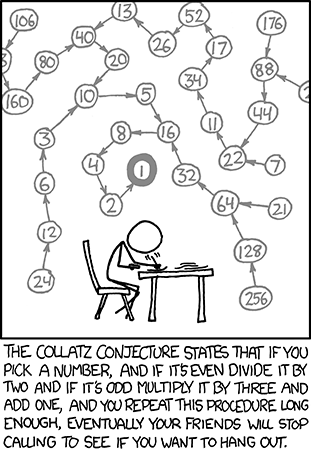
- "Vezměme jakékoliv kladné celé číslo n. Pokud je n sudé číslo, vydělíme jej dvěma, získáme tak n / 2. Pokud je n liché číslo, vynásobí se třemi, přičte se jedničku, tj. 3n + 1. Tento postup se dále opakuje. Domněnka je taková, že nezáleží na tom, jaké počáteční číslo n je zvoleno – výsledná posloupnost vždy nakonec dojde k číslu 1."
- Vstup = číslo n, vypisujte jednotlivé kroky, nakonec vypište počet kroků.
-
Dělitelnost vhodně zjistíme pomocí operátoru modulo (zbytek po dělení):
-
17 % 2 # vrací 1
-
24 % 2 # vrací 0
-
-
inventura v zoo
-
každý řádek vstupu (každý input() ) je zvíře, např::
- tygr
- lev
- luskoun
- lenochod
- tygr
- lev
- orangutan
- bobr
- tygr
- kanec
- ptakopysk
- konec
- vstup končí slovem "konec"
-
postupně několik úloh (všichni by měli zvládnout aspoň úlohy 1-6, podle času i víc až všechny)
-
Čtěte vstup, pro každé zvíře vypište "V zoo je zvíře"
- tj. například pokud je na vstupu ondatra, vypište "V zoo je ondatra"
- Je v zoo tygr?
- Kolik je v zoo kusů zvířat?
- Kolik je v zoo tygrů?
- Kolik je v zoo tygrů a kolik lvů?
-
Porovnávání zvířat trapně
- Vždy po dvě po sobě jdoucí zvířata A B vypište "A je lepší než B"
- např. "orangutan je lepší než bobr"
- tj. musíte si vždy pamatovat, které zvíře máte teď i které zvíře jste měli minule (a to co máte teď se stane pro další otočku cyklu zvířetem minulým)
- a taky pro první zvíře ještě nemůžete nic říct, nejdřív musíte načíst dvě zvířata...
-
Jak je dlouhý tygr? Tygr je dlouhý 4. A ptakopysk je dlouhý 9.
-
len("ptakopysk") - Vypište postupně každé zvíře v zoo a jeho délku.
-
- Jaká je celková délka všech zvířat v zoo?
- Jak dlouhé je nejdelší zvíře?
- A které to je?
-
Porovnávání zvířat podle délek
- Pro každá dvě po sobě jdoucí zvířata vypište, které je delší než které:
- lev je kratší než oragnutan
- orangutan je delší než bobr
- bobr je stejně dlouhý jako tygr
-
Čtěte vstup, pro každé zvíře vypište "V zoo je zvíře"
-
každý řádek vstupu (každý input() ) je zvíře, např::
24.10.
-
na přednášce bylo (?)
- for
- list (seznam, pole)
- funkce? -- to můžem nechat na jindy
-
inventura v zoo pomocí listu a for-cyklu, další úlohy (předpokládám že stihneme zhruba prvních 11 úložek, uvidíme)
- Vytvořte si seznam zvířat v zoo jako list (s opakováním, některé zvíře může být víckrát).
- Vypište všechna zvířata.
- Kolik je v zoo tygrů?
- Vypište třetí zvíře.
- Vypište předposlední zvíře.
- Vypište prvních 10 zvířat.
- Vypište posledních 5 zvířat.
- Vypište každé druhé zvíře.
- Vypište všechna zvířata začínající na L.
-
Vytvořte seznam všech zvířat začínajících na L (a nějak ho vypište).
- Do seznamu se přídává pomocí seznam.append(zvire)
-
Počet po sobě jdoucích zvířat od L.
- Nechť občas po sobě následuje několik zvířat, která všechna začínají na L.
- Meziúloha: pro každou sekvenci po sobě jdoucích zvířat od L vypište její délku.
- Úloha: jaký je maximální počet po sobě jdoucích zvířat od L?
- Aneb jaká je maximální délka souvislé posloupnosti zvířat začínajících na L?
-
Návodné myšlenky:
- pokud jsem teprve začal, tak dosavadní maximální délka je 0
- pokud aktuální zvíře nezačíná na L, tak aktuální délka posloupnosti zvířat na L je 0
- pokud aktuální zvíře začíná na L, tak aktuální délka posloupnosti zvířat na L je o 1 vyšší než byla v předchozím kroku
- je aktuální délka posloupnosti zvířat na L vyšší než dosavadní maximum?
- v této úloze není nutné si pamatovat tu samotnou posloupnost zvířat, stačí si pamatovat její délku
- Tip: vyřešení této úložky vám pomůže při řešení domácího úkolu.
- Vypište zvířata v maximální souvislé posloupnosti zvířat na L.
- Maximální počet po sobě jdoucích zvířat začínajících stejným písmenem.
-
Vypište postupně všechna zvířata začínající na jednotlivá písmena slova dikobraz
- Pro procházení všech písmen slova můžete slovo nejdřív převést na seznam list("dikobraz")
-
Ale ani to není nutné, přes string jde i přímo iterovat for cyklem, takže stačí přímo použít
-
for pismeno in "dikobraz":
-
- Vypište nejdřív všechna zvířata začínající na a, pak všechna začínající na b, a tak dále, až po všechna začínající na z
-
Z důvodu koronaviru Pražská zoo zkrachovala a všechna zvířata se přesunou do Plzeňské zoo.
- Udělejte si dva seznamy zvířat, jeden pro Prahu a jeden pro Plzeň.
- Spojte seznamy dohromady.
-
Vzniká nová zoo na Kladně!
- Vezměte zase seznam zvířat v Plzni a v Praze.
- Na Kladno půjde první třetina zvířat z Prahy a poslední třetina zvířat z Plzně.
- Délku seznamu zjistíte len(seznam)
-
Křížení zvířat
- Zkřižte zvířata, která jsou vedle sebe
- Dvě zvířata zkřížíte tak, že vezmete první půlku prvního zvířete a druhou půlku druhého zvířete
- Např. ovce+tygr = ovgr, kapybara+velbloud = kapyloud...
- Obrácená úloha: pro křížence najděte jeho rodiče
- zdrojáky ze cvika: zoo.py.txt
31.10.
-
na přednášce bylo
- funkce -- na ty mrkneme
- třídy a objekty -- ty si asi necháme na jindy
- na Algoritmizaci už byly sorty, takže i ty procvičíme
-
- vše bylo na přednášce Algoritmizace, případně si připomeňte například zde: https://youtu.be/ROalU379l3U
- na cvičení jsme si udělali bubble sort, pořádně si to procvičíte v domácím úkolu
-
hlavní téma: funkce
-
stručně projít a ukázat to hlavní o funkcích
-
def umocni(zaklad, exponent=2): vysledek = zaklad**exponent return vysledek cislo = 5 cislo_na_druhou = umocni(5) print(cislo_na_druhou) print( umocni(10) )
print( umocni(10, 3) )
print( umocni(zaklad=10) )
print( umocni(zaklad=10, exponent=4) )
print( umocni(exponent=4, zaklad=10) )
print( umocni(10, exponent=4) )
-
- další cvičeníčko: naprogramujte funkci najdi_minimum(seznam)
-
co používat opatrně
-
funkce které mění to co dostaly jako vstupní argumenty (porušuje koncept "single-entry single-exit")
- typicky by funkce měla vstupní argumenty používat read-only
- výstup by si měla vyrobit ve vlastní proměnné (proměnných) a tu (ty) vrátit pomocí return
-
ale pokud třeba má funkce upravovat seznam, pak je neefektivní ho kvůli tomu kopírovat
- příklad: setrid_seznam(seznam)
- příklad: půjčíte kamarádovi fyzikální tabulky, aby si v nich něco našel, a on vám v nich přepíše vzorečky
- příklad: půjčíte kamarádovi sešit, aby vám do něj napsal domácí úkol
-
funkce které mění to co dostaly jako vstupní argumenty (porušuje koncept "single-entry single-exit")
-
co pokud možno NEpoužívat (kromě případu kdy k tomu máte dobrý důvod a víte co děláte)
-
definice funkce uvnitř definice funkce
- to je zbytečně složité a navíc je to imho k ničemu
-
funkce které využívají globální parametry
- je snesitelné je používat read-only (ale i tak je čistší je předávat přes argumenty)
- je vysloveně nevhodné je měnit (a tam navíc snadno hrozí že to člověk naprogramuje špatně)
- příklad: půjčíte kamarádovi tužku a on vám během psaní ještě sní svačinu
-
definice funkce uvnitř definice funkce
-
stručně projít a ukázat to hlavní o funkcích
- cvičení: funkce na úlohy z minulého cvičení
- Zdrojáky ze cvika: funkce.py.txt najdimin.py.txt setrid.py.txt
-
domácí úkol: sort
- implementujte aspoň jednu metodu třídění
- pokud jich implementujete víc, dostanete bonusové body
- v kódu definujte a následně použijte aspoň jednu funkci!
-
Pozor, váš cvičící má problém rozlišovat pojmy funkce a metoda a volně je zaměňuje!
- vy se to naučte tak jak se to učí na přednášce, ať pak nemáte problémy u zkoušky z Programování 2
7.11.

- tip: cvičeníčka viz odkazy dole nastránce
-
dnes:
- třídy a objekty
- spojové seznamy?
- rekurze?
- cvičení: tichá pošta
-
jednoduché objekty a metody
- třída Clovek
- má jmeno
- má metodu rekni(text)
- má metodu pozdrav
-
class Clovek: def __init__(self, jmeno): self.jmeno = jmeno def rekni(self, text): reknu = self.jmeno + ': ' + text print(reknu) return reknu def pozdrav(self): self.rekni("Ahoj, jsem " + self.jmeno) rudolf = Clovek('Rudolf') rudolf.rekni('ptakopysk') rudolf.pozdrav()
-
dědičnost
- řvoun je člověk, který řekne text NAHLAS
- sprosťák je člověk, který promluvu končí "vole"
- anonym je člověk, který neříká své jméno
- zapomínáč je člověk, který zapomene první půlku toho co měl říct a řekne jen druhou půlku
- pokémon je člověk, který umí říkat jen svoje jméno (třeba tak že místo každého slova řekne svoje jméno)
- němý je člověk, který neříká nic
- ...
-
class Rvoun(Clovek): def rekni(self, text): reknu = self.jmeno + ': ' + text.upper() print(reknu) return reknu petr = Rvoun('Petr') petr.pozdrav()
-
tichá pošta v listu
- dám pár lidí do listu, postupně tichá pošta
-
zprava = "Na stropě je chleba s máslem, pošli to dál." lidi = [...] for clovek in lidi: zprava = clovek.rekni(zprava)
-
lineární spojové seznamy (tzv. spojáky)
- volitelně s hlavou, s ocasem, cyklické, obousměrné
- procvičit u tabule?
- cvičení: tichou poštu překlopit do spojáku
-
tichá pošta ve spojáku
- lidi jsou ve spojáku, každý ví kdo je po něm
- vytvořit (postupně)
- projít (vypsat)
- posílat si text (s rekurzí či bez rekurze)
-
def rekni(self, zprava): print(self.jmeno, zprava, sep=':') return zprava
def rekni(self, zprava): zprava = zprava + " vole" print(self.jmeno, zprava, sep=':') return zprava
clovek = Clovek("Petr") clovek.dalsi = ... while clovek.dalsi != None ... def posli_to_dal(self, zprava): zprava = self.rekni(zprava) if self.dalsi != None: self.dalsi.posli_to_dal(zprava)
- Zdrojáky ze cvičení: posta.py.txt
-
další operace (asi až příště)
- vkládat (na začátek, na konec, za Petra, před Petra)
- mazat (vše, poslední prvek, první prvek, Petra)
- obrátit spoják
14.11.
-
dnes: Oranžový Expres (aneb další operace se spojáky, tentokrát s vlaky)

- na přednášce byly funkce a objekty, to beru jako že už víceméně umíme
-
připravit: spoják vlak
-
vlak je takový dobrý příklad spojového seznamu
- vlak má jednu mašinu a 0 až N vagonů
- mašina ví jen co je za ní za vagon (nebo že za ní žádný vagon není)
- vagon ví, co veze, kolik toho veze, a který vagon je za ním (nebo že za ním žádný vagon není)
- (vagon by mohl vědět i který vagon je před ním; to by pak byl obousměrný spojový seznam, to si volitelně můžete zkusit taky -- je víc práce ho udržovat, protože se musí opravovat dvakrát tolik odkazů, ale některé operace se s ním dělají o trochu pohodlněji)
-
vyrobte si definice tříd Masina a Vagon podle popisu výše
- u každá třídy stačí když vyrobíte metodu __init__() která nastaví příslušné datové položky (ale pokud chcete, udělejte si i další metody)
- příklad (naznačený):
-
class Masina: def __init__(self, vagon_za_mnou=None): self.dalsi = vagon_za_mnou class Vagon: def __init__(self, naklad="brambory", mnozstvi=0, za_mnou=None): ...
-
vyrobte si jeden vlak ("Oranžový Expres"), který bude mít aspoň 5 vagonků vezoucích různý náklad
- vagon může vézt například uhlí, dřevo, papír, krávy nebo zrní
- množství můžete chápat jako číslo bez zřejmého rozměru; pro krávy má asi smysl mluvit o jejich počtu, pro zrní spíš o tunách
-
stejně jako v domácím úkolu nepoužívejte žádné listy, v nějaké proměnné si udržujte pouze mašinu, a přes tu pak budete přistupovat k vagonům (můžete samozřejmě použít nějaké dočasné proměnné při vytváření vlaku, ale ty berme skutečně jako dočasné)
- například:
-
masina = Masina() masina.dalsi = Vagon() masina.dalsi.dalsi = Vagon("uhlí") masina.dalsi.dalsi.dalsi = Vagon("koťátka", 3) ...
-
tímto nám vznikl takzvaný seznam "s hlavou", tedy se speciálním prvkem (mašinou), který vždy existuje a odkazuje na první skutečný prvek seznamu (první vagon)
- seznamy s hlavou jsou výhodné, snadněji se s nimi pracuje, neboť nemusíte tak složitě ošetřovat speciální případy jako přidání prvního vagonu, přidání vagonu na začátek, odebrání prvního vagonu (tedy prvku)...
- tím máme připravený základní vlak, se kterým teď budeme cvičit
-
vlak je takový dobrý příklad spojového seznamu
-
úložky s vlakem
-
pro každou úlohu vytvořte na mašině novou metodu
- pokud možno parametrizovatelnou, tj. výchozí hodnota metody pridej_na_zacatek může být přidat vagon vezoucí 30 ptakopysků, ale mělo by být možné pomocí parametrů přidat i vagon vezoucí něco jiného
- metoda teoreticky buď vytvořit vagon dle zadání, ale lepší asi je, pokud ta metoda dostane už vytvořený vagon jako parametr, to se vám bude hodit v některých cvičeních
- pro přehlednost je vhodné, pokud každá metoda bude vypisovat, co dělá
- některé úlohy mohou být pro vás vlak nesmyslné (třeba hledat vagony kde je množství nákladu víc než 30 pokud takové nemáte), v tom případě si buď upravte vlak anebo zadání úlohy :-)
- jsou naznačené i bonusové úlohy, které programovat nemusíte (ale pokud chcete, tak můžete); ty jsou určené spíš pro ty, kteří jsou se standardními úlohami příliš rychle hotovi a pak se nudí (a pro ostatní případně dobrovolně na doma)
-
část 1 Nádraží: přidávání a prohledávání
-
přidejte na začátek vlaku (hned za mašinu) vagón vezoucí 30 ptakopysků
- jakou asymptotickou složitost má tato metoda?
-
přidejte na konec vlaku (za poslední vagon) vagón vezoucí 50 bublin
- jakou asymptotickou složitost má tato metoda?
- jak upravíte mašinu, abyste tuhle operaci zvládli v konstantním čase?
-
vypište všechny vagony, které vezou náklad v množství aspoň 10
- bylo by hezké, kdyby člověk mohl udělat prostě print(vagon) a Python by místo něčeho jako __main__.Vagon object at 0x7fab3d588358 vypsal třeba něco jako Vagon vezouci drevo v mnozstvi 30
- toho lze snadno dosáhnout předefinováním metody __str__(self) kterou Python používá pro přetypování objektu daného typu na string (takže ta metoda musí vracet string!)
-
hodí se taky umět nějak kombinovat stringy a proměnné
- na to je v Pythonu několik metod, používejte libovolnou z nich
- Rudolf nejraději používá metodu str.format(), která ve stringu nahrazuje složené závorky {} za hodnoty proměnných dodaných jako parametry
-
naklad = 'uhlí' mnozstvi = 10 popis = f'Vezu {naklad} v množství {mnozstvi}' print(popis) # vypíše: Vezu uhlí v množství 10. - má to i další možnosti jako uvnitř těch složených závorek specifikovat, který parametr tam vložit, jak ho zformátovat...
-
bonusová úloha: vypište celkové množství jednotlivých typů nákladu
- a zkuste to zase bez listů a bez dictů (jak efektivní to bude?)
- najděte vagon s největším nákladem
-
za vagon s největším nákladem připojte nový vagón obsahující 2 policisty
- hledání vagonu s největším nákladem neprogramujte znova; kopírování kódu je častým zdrojem chyb (a proto se mu vyhýbáme), místo toho programujeme funkce a metody tak, abychom jednou napsaný kód mohli opakovaně využít!
- za vagon s policisty připojte nový vagon se zlatem
- přidejte za mašinu vagon s uhlím
- naložte nějaké uhlí do mašiny (snižte množství uhlí ve vagonu na polovinu)
- a zase ten vagon odeberte
- připojte někam vagon vezoucí vodu
-
a jedeme! (bonus)
- to programovat nemusíte
- ale můžete, naprogramujte třeba nějakou jednoduchou textovou animaci
- hodit se vám asi bude Pythonová funkce, která prostě jen počká zadaný čas, například 1 sekundu:
-
import time print(masina) time.sleep(1) print(masina.dalsi)
-
přidejte na začátek vlaku (hned za mašinu) vagón vezoucí 30 ptakopysků
-
pro každou úlohu vytvořte na mašině novou metodu
-
-
část 2 Banditi: odebírání a přerovnávání
- Vytvořte nový vlak ("vlak banditů"), který obsahuje jedniný vagon a v něm 5 banditů.
- Banditi přepadli vlak! Přepojte vagon s bandity za mašinu našeho vlaku.
- (Bonus) Banditi běhají po střeše vlaku, takže běžně obsah vagonů neovlivňují. Jinak bychom museli umožnit, aby vagon mohl obsahovat i více druhů nákladu, a přesun banditů po vlaku realizovat tím, že se vždycky odečtou z jednoho vagonu a přičtou do následujícího... To programovat nemusíte (ale případně můžete).
-
Banditi našli vagon s policisty a zabili je!
- Najděte vagon, ve kterém jsou policisti, a nastavte v něm množství nákladu na 0 (anebo typ nákladu na "mrtví policisti"...)
-
Banditi jdou ukrást vagon se zlatem (ale nevědí, kde je, takže ho musejí nejprve najít)
- Najděte vagon, jehož nákladem je zlato
- Vypojte ho z vlaku (ale vlak zase spojte zpátky dohromady)
- Vagon napojte na vlak banditů
-
Banditi zametají stopy: přepojte vagon s mrtvými policisty před vagon s vodou
- Opět předpokládejte, že ani o jednom banditi nevědí, kde je, takže každý z těchto vagonů je nejdřív potřeba najít
- Pozor, v jednosměrném seznamu je připojování před konkrétní vagon složitější než připojování za konkrétní vagon. Rozmyslete si, co s tím.
- Banditi odjíždějí... Přepojte vagon s bandity zpátky na vlak banditů.
-
část 3 Druhé nádraží (tohle už jsou spíš bonusy... ale na domácí úkol jsou některé z nich dobrou průpravou)
- Za každý vagon s množstvím nákladu více než 30 přidejte vagon s policisty v počtu odpovídajícím desetině množství nákladu
- Najděte vagon s vodou a zdvojte ho
- Najděte dvojice sousedních vagonů, které vezou totéž, a přeložte to do druhého z nich, první vypojte.
- Rozdělte vlak na dva, do jednoho vlaku dejte vagony vezoucí věci od písmen A-K, do druhého ostatní (stringy jde porovnávat nejen na rovnost, ale i na větší/menší než)
- Najděte všechny vagony s množstvím nákladu menším než 10 a přepojte je na konec vlaku se zachováním jejich pořadí (zamyslete se nad složitostí)
-
Otočte vlak, tj. přeskládejte vagonu do jiného vlaku, kde budou v opačném pořadí
- Jakou to bude mít složitost? Zkuste to v lineárním čase (ale pochopitelně stále bez listů a podobných struktur).
-
Seřaďte vlak podle objemu nákladu od nejnižšího k nejvyššímu
- Aneb implementujte nějaký sort nad spojovým seznamem
- Některé sorty jsou na to vhodnější než jiné
- Minimálně jeden ze sortů lze pohodlně implementovat i nad jednosměrným spojovým seznamem
- Jiné sorty zase může být o hodně pohodlnější dělat nad obousměrným spojovým seznamem
-
část 2 Banditi: odebírání a přerovnávání
- Zdroják ze cvika: vlak.py.txt
21.11.
- dnes: čtení ze souborů a psaní do souborů; dict
- vím že BMI jsme už dělali, o to snazší to pro vás bude
-
koho by nebavilo dělat to co už dělal, tak si to upravte a dělejte něco jiného, například:
- vstupem je nějaký textový soubor s textem v angličtině (třeba kus genesis)
- část 1 přeskočte
- část 2: spočítejte počet řádků a počet slov v textu, průměrný počet slov na řádek, průměrnou délku slova ve znacích... vypište celý text ale z každého slova vypište jen první 3 znaky... vypište jen slova začínající velkým písmenem ("Aaaa".istitle())...
- část 3: vypište výsledek do souboru místo na standardní výstup
- část 4: vyrobte si v dictu malý překladový slovníček a pomocí něj některá anglická slova ze vstupu přeložte do češtiny a vypište text takto částečně přeložený (pokud je slovo ve slovníčku, vypište ho česky, pokud ne, vypište původní anglické slovo); případně i interaktivní mód kde načtete slovníček ze souboru do dictu, uživatel pak zadá slovo/slova a vy slovo po slově přeložíte
- zkrátka postupujte přibližně podle popisu cvičení níže, akorát prostě místo BMI pracujte s textem...
-
cvičení: výpočet BMI (volitelné součásti dělejte jen pokud chcete a jen pokud máte hotový základ)
-
část 1: interaktivní výpočet BMI -- tohle už máte hotové ze dřív
- napište jednoduchý program (který pak budeme v dalších částech cvičení upravovat)
- program se zeptá uživatele na vstup, a to na jeho hmotnost (v kilogramech) a výšku (v metrech)
- volitelné: přijímejte vstup v různých formátech (například s desetinnou čárkou místo desetinné tečky)
- vypočítejte uživatelovo BMI, dle vzorečku hmotnost / výška2
-
vypište, zda má uživatel váhu v pořádku, či zda má podváhu či nadváhu
- normální váha je při BMI 18.5 až 25, méně je podváha, více je nadváha
- volitelně: vypište podrobnější hodnocení
- volitelně: řekněte uživateli, jaké je pro jeho výšku rozmezí ideální váhy (např. od 85.7 kg to 98.2 kg)
- volitelně: se znalostí průměrné hustoty lidského těla (1000 kg/m3) odhadněte objem uživatele, a spočítejte například, jaký by měl uživatel průměr a obvod, pokud by měl stejnou výšku ale tvar válce, případně jaký by měl průměr a obvod, pokud by měl tvar koule
-
část 2: načíst vstupy ze souboru
- vstup je teď v souboru, který má na každém řádku tři informace oddělené mezerou: jméno hmotnost výška
-
soubor si vyrobte, může vypadat např. takhle:
-
Rudolf 83.3 1.78
Anna 56.2 1.62
August 130 1.3
-
Rudolf 83.3 1.78
-
načítejte postupně data ze souboru; vyberte si jednu z možností jak pracovat se souborem:
-
drzadlo = open('vstup.txt', 'r')
for radek in drzadlo:
polozky = radek.split() -
with open('vstup.txt', 'r') as drzadlo:
for ...
-
drzadlo = open('vstup.txt', 'r')
-
nastudujte si jak funguje na stringách metoda split()
- podle nějakého oddělovače naseká string na kousky a vrátí to jako list
-
pokud zadáte oddělovač -- třeba '.' -- tak kousky oddělené oddělovačem budou tvořit prvky vráceného listu (a můžou být i prázdné)
-
"Ahoj. Já jsem Rudolf... Super, že.".split(".") # vrátí následující list: ["Ahoj", " Já jsem Rudolf", "", "", " Super, že", ""]
-
-
pokud ale oddělovač nezadáte, split se chová magicky, oddělovačem je jeden nebo několik bílých znaků (mezera, konec řádku, tabulátor...) a vrácený seznam nemá prázdné prvky; což právě člověk dost často chce!
-
" Ahoj já jsem Rudolf ".split() # vrátí následující list: ["Ahoj", "já", "jsem", "Rudolf"]
-
- pokud máte soubor ve stejné složce ve které spouštíte Python, mělo by to fungovat
-
pokud máte soubor jinde, můžete zadat místo názvu souboru celou cestu, např.:
- open('C:\Documents and Settings\Dokumenty\vstup.txt', 'r')
- v Recodexu vždy bude soubor ve stejné složce takže stačí jen jméno souboru
- pro každý řádek spočítejte BMI člověka a vypište hodnocení na výstup
- volitelně: spočítejte a vypište nějaké statistiky celého souboru, například průměrnou výšku, hmotnost a bmi, směrodatné odchylky, počet lidí s jednotlivými kategoriemi dle BMI, medián BMI, modus kategorie BMI...
-
část 3: vypsat výstupy do souboru
- hodnocení jednotlivých lidí nepište na standardní výstup, ale do souboru; vyberte si jednu z možností jak pracovat se souborem (když soubor po psaní nezavřu, tak se to co jsem do něj psal neuloží!):
-
zapisovadlo = open('vysledek.txt', 'w')
...
print(a, b, c, file=zapisovadlo)
...
zapisovadlo.close() -
with open('vysledek.txt', 'w') as zapisovadlo:
...
(zavře se samo) - volitelně: uživatel má možnost si zadat jména souborů (ale pokud nezadá, použije se nějaká výchozí hodnota)
- volitelně: vytvořte i druhý soubor, kam zapíšete souhrnné statistiky
-
část 4: načíst data ze souboru, pak interaktivně odpovídat na dotazy o jednotlivých lidech
-
budeme potřebovat dicty
-
dict lze chápat jako slovník, ale lepší je to chápat jako tabulku o dvou sloupcích
- první sloupec je klíč, ten musí být unikátní a musí to být nějaký jednoduchý typ (string, int, float, tuple), pod klíčem do dictu ukládáme hodnoty a zase je v něm hledáme
- druhý sloupec je hodnota, která je tam pod daným klíčem uložená, a může být libovolného typu (string nebo jiný jednoduchý typ, ale klidně i celý list, dokonce i dict, tj. můžete například mít dict dictů...)
-
takže například takovýhle dict:
-
mesice = dict()
mesice['leden'] = 31
mesice["unor"] = 28
mesice[2] = 28
-
mesice = dict()
-
odpovídá takovéhle tabulce:
-
klíč hodnota 'leden' 31 'únor' 28 2 28
-
- stejné hodnoty se můžou opakovat, ale klíče nikoliv -- pokud pro stejný klíč potřebujete uložit víc hodnot, musíte to nějak obejít, například tam pro ten klíč jako hodnotu uložit list a do něja dát ty jednotlivé hodnoty které tam chcete mít
-
čtení i zapisování se u dictu dělá přes notaci dict[klíč], a na přítomnost klíče se můžu ptát pomocí "in", např.:
-
mesice[2] = 29 # už existovalo, změnil jsem
mesice[3] = 31 # ještě neexistovalo, vytvořil jsem
delka_ledna = mesice['leden']
delka_brezna = mesice['brezen'] # spadne, klíč neexistuje!
if 'brezen' in mesice: # True pokud klíč existuje, nespadne
delka_brezna = mesice['brezen']
else:
print('Délku března neznám.')
-
mesice[2] = 29 # už existovalo, změnil jsem
-
dict lze chápat jako slovník, ale lepší je to chápat jako tabulku o dvou sloupcích
-
a teď k úloze
- data o lidech ze vstupního souboru si uložte do dictu
- klíčem je jméno, hodnotou je BMI
-
obezity = dict()
...
obezity[jmeno] = hodnoceni - interaktivně se ptejte uživatele na jméno člověka
- pokud člověka znáte, vypište jeho BMI a hodnocení
- pokud ne, oznamte to
-
if klic in muj_dict:
hodnota = muj_dict[klic]
- volitelně: interaktivní část je ve while cyklu, v každé obrátce odpoví na jeden uživatelův dotaz na jméno
- +volitelně: po zadání speciálního vstupu (např. "konec") vypíše souhrnné statistiky o lidech, na které se uživatel ptal, a ukončí se
- +volitelně: v cyklu jen uživatel zadává jména, program jen potvrzuje, po ukončení speciálním vstupem vypíše výstupy do souboru
-
budeme potřebovat dicty
-
část 1: interaktivní výpočet BMI -- tohle už máte hotové ze dřív
- Zdrojáky ze cvika: pokus_s_dicty.py.txt bmi2.py.txt bmi.txt
28.11.
- rekurze
-
úloha 1: faktoriál (společně)
- vytvořte funkci faktorial(n), která pro přirozené číslo n vrací n!
- varianta bez rekurze: for-cyklus
-
varianta s rekurzí
- pro n = 1 rovnou vrátíme 1
- pro n > 1 vrátíme n*faktorial(n-1)
- tj. funkce zavolá samu sebe pro n o 1 menší, a až se vrátí výsledek, vynásobí ho n a vrátí
- je dobré si to prokrokovat a podívat se jak se zanořují volání té funkce a pak se zase vynořují
-
dobré je i tušit, jak se to vyhodnocuje
- když dojde na volání funkce, uloží se aktuální stav výpočtu na zásobník
- provede se funkce
- funkce vrátí návratovou hodnotu (return)
- ze zásobníku se obnoví předchozí stav výpočtu, na místo volání funkce se jakoby dosadí návratová hodnota
-
úloha 2: Matfyzák v obchodě (zaplacení částky mincemi)
- Matfyzák nakupuje v obchodě, má nákup za celkovou cenu N (to je tedy vstup)
- Matfyzák má nekonečně mnoho pětikorunových, dvoukorunových a korunových mincí
- Matfyzáka zajímá, jakými všemi způsoby může částku zaplatit
-
vypište všechny možné kombinace mincí, které dávají správný součet
- na pořadí nezáleží, tj. 5+2 je totéž jako 2+5
- (tip: co takhle hledat jen monotónní posloupnosti mincí?)
-
řešte to pomocí rekurze!
-
tip: chci nějak zaplatit 43 Kč, tak dám třeba 5 Kč, a tím jsem to převedl na problém jak zaplatit 38 Kč
- anebo dám 2 Kč, a pak řeším jak zaplatit 41 Kč
-
tip: vypisovat mince průběžně sami zjistíte že není dobrý nápad
- lepší nápad je vždycky vypsat kombinaci mincí až když dojdete k 0
- je tedy potřeba si do vnořené funkce nějak předávat seznam již použitých mincí
- možností jak to udělat je víc, zkuste dát dohromady nějakou fungující variantu
- a pak se případně zamyslete/zamyslíme nad efektivitou
-
tip: chci nějak zaplatit 43 Kč, tak dám třeba 5 Kč, a tím jsem to převedl na problém jak zaplatit 38 Kč
-
úloha 3: zaplacení částky mincemi s omezenou zásobou mincí (možná to stihneme, možná ne a bude to tedy úloha navíc)
- úprava: mincí je omezená zásoba
- pro účely téhle úlohy si klidně "natvrdo" vytvořte nějaký dict, ve kterém budete mít uloženo, kolik máte k dispozici kterých typů mincí (anebo si vymyslete, jak to na vstupu zadat)
-
nyní je potřeba si vždy hlídat aktuální stav zásoby mincí
-
buď při rekurzivním volání předat funkci kopii stavu zásob mincí s aktuálními hodnotami
- to je o chlup jednodušší na naprogramování, ale méně efektivní, protože se furt něco kopíruje
-
nebo to nekopírovat, používat jen jednu globální zásobu
- při rekurzivním volání se aktualizuje zásoba odebráním použíté mince
- a po vynoření z rekurze se tam ta použitá mince zase musí vrátit! Backtrackujeme, aneb vracíme se po vlastních stopách do předchozího stavu, tak musíme zajistit, aby ten předchozí stav seděl se vším všudy.
- to je o chlup náročnější na naprogramování, ale výpočetně efektivnější, protože se ušetří to kopírování
- a třeba vymyslíte i jinou variantu
-
buď při rekurzivním volání předat funkci kopii stavu zásob mincí s aktuálními hodnotami
- domácí úloha: domino
- zdrojáky ze cvika: zaplatit.py.txt fakt1.py.txt
5.12.
-
z minula chybí
- jak načítat standardní vstup po řádkách bez zarážky na konci
-
připomenout
- zadání zápočtových programů
- prohledávání do hloubky a do šířky
-
Cesta králem na šachovnici (délka) -- viz Recodex
- Program bude hledat nejkratší cestu šachovým králem na šachovnici 8x8, kde na některá políčka nelze vstoupit.
-
Zamyšlení nad tím jak to řešit
- samostatně
- ve dvojicích/skupinkách
- společně
- Řešení
-
Bonus (není v Recodexu): vypište též seznam políček, po kterých má král jít
-
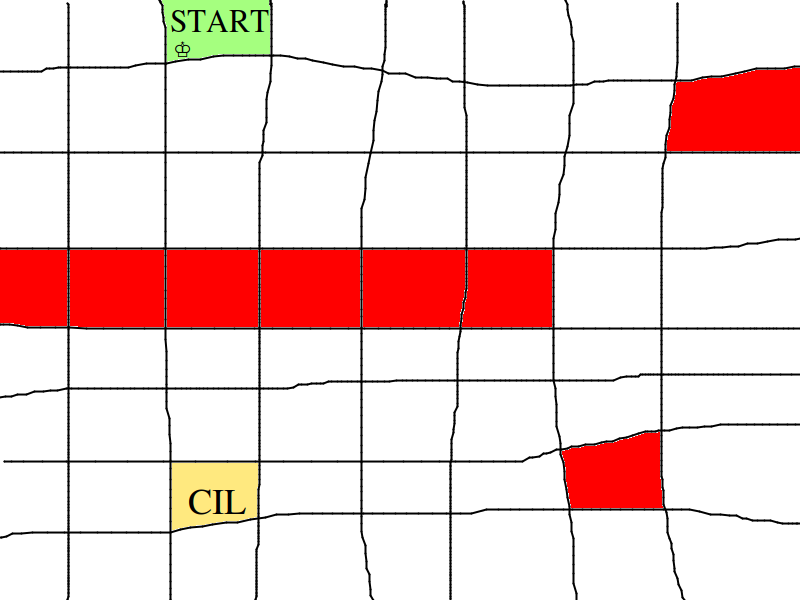
-
Jezdec na obdélníkové šachovnici -- viz Recodex
- V této úloze budete pro zadanou šachovnici a zadanou pozici jezdce na šachovnici rozhodovat, zda může jezdec postupně projít celou šachovnici tak, aby každé její pole navštívil právě jednou.
- Opět nejdřív zamyšlení a pak řešení...
-
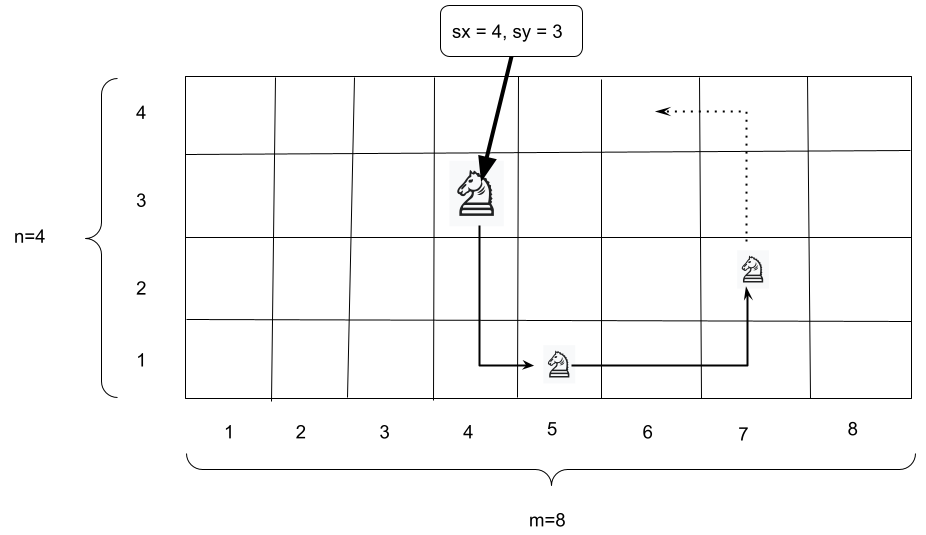
-
Dnes se v Recodexu objevuje poslední domácí úkol "Cesta věže"
- Tím jsou zadány všechny úkoly
- Standardní počet bodů za úkoly je 100
- Je třeba získat aspoň 80%, tj. aspoň 80 bodů
- K získání bodů lze využít i bonusové úlohy
-
Za body nad limit 80 bodů získáváte více času na zápočtový test, v poměru 1 minutu navíc za každý bod
- Pokud např. na zápočtový test bude 75 minut a máte v Recodexu 93 bodů, máte na test 75+(93-80) = 88 minut
-
Pokud zbude čas tak ještě binární vyhledávací strom
- uzel obsahuje například jméno člověka a jeho věk (věk je klíčem)
-
úlohy
- vložit prvek do BVS
- vyhledat prvek podle klíče
- nalézt maximum
- určit počet uzlů ve stromě
- určit výšku stromu
- volitelně další operace (např. delete); ale to si všechno můžete procvičit na bonusové Recodexové úloze "Banka" (TODO pokud ji Rudolf zadá)
12.12.
- co zbylo: testy, výjimky, asserty, list comprehension, moduly a balíčky, name=main, defaultdict, set, tuple...
-
defaultdict
-
pocty_slov = dict() ... if "slovo" not in pocty_slov: pocty_slov["slovo"] = 1 else: pocty_slov["slovo"] += 1
-
from collections import defaultdict pocty_slov = defaultdict(int) ... pocty_slov["slovo"] += 1 # pokud klíč neexistuje, vrací pro něj výchozí hodnotu, což pro int je 0
-
seznamy_jmen = defaultdict(list) ... seznamy_jmen["R"].append("Rudolf") # výchozí hodnota pro list je prázdný list
-
-
list comprehension
-
# klasicky texty = ['5', '8', '10', '20'] cisla = [] for text in texty: cisla.append( int(text) )
-
# více Pythonovsky pomocí list comprehension texty = ['5', '8', '10', '20'] cisla = [ int(text) for text in texty ]
-
# klasicky mocniny_sudych = [] for cislo in cisla: if cislo % 2 == 0: mocniny_sudych.append( cislo**2 )
-
# více Pythonovsky pomocí list comprehension mocniny_sudych = [ cislo**2 for cislo in cisla if cislo % 2 == 0 ]
- atd., může to být i celkem složité, lze i dict comprehension, lze i něco co vypadá jako tuple comprehension ale ve skutečnosti je to líně vyhodnocovaný generátor...
-
na list (a tedy i na list comprehension) jde aplikovat např. max(muj_list), sum(muj_list), muj_list.len()
- jak spočítáte průměr z hodnot v listu?
-
-
set
-
a = {5, 6, 7} a.add(5) a.add(10) 10 in a a.remove(6) a.discard(20) b = {5, 10, 20} a.intersection(b) a & b a.union(b) a | b a.difference(b) a - b
-
-
výjimky
-
try: něco kde může nastat chyba except TypOčekávanéChyby: nespadni ale poraď si s chybou except TypJinéOčekávanéChyby as e: poraď si i s touto chybou print(e) except: poraď si s libovolnou jinou chybou # ale asi nejde o očekávanou chybu, takže asi je lepší spadnout
-
-
assert
-
assert epsilon > 0, "Předpokládáme, že epsilon je vždy kladné!"
-
-
moduly a balíčky (packages)
-
import collections d = collections.defaultdict()
-
from collections import defaultdict d = defaultdict()
-
from my_other_file import MyClass from scitadlo import Scitadlo
-
if __name__ == '__main__':
-
from my_directory.my_file import *
-
- zdrojáky z cvika: zbytky.py.txt lidi.py.txt posta.py_0.txt
19.12.
testování
- můžete testovat zcela ručně, ale lepší je to s testovacími balíčky
- pytest je jednodušší (unittest je standardnější)
- Jak testovat ve VS Code: https://code.visualstudio.com/docs/python/testing
-
class Scitadlo: def secti(a, b): return a + b -
# "Ruční" testování from scitadlo import Scitadlo def test_jedna_dva(): assert Scitadlo.secti(1, 2) == 3 def test_zaporne(): assert Scitadlo.secti(1, -2) == -1 test_jedna_dva() test_zaporne() -
# Pytest # Testovací skript je skript jehož jméno začíná "test_" # Importovat pytest obvykle ani není potřeba import pytest from scitadlo import Scitadlo # Test je funkce jejíž jméno začíná "test_" def test_jedna_dva(): # testuje se pomocí assertů assert Scitadlo.secti(1, 2) == 3 def test_zaporne(): assert Scitadlo.secti(1, -2) == -1 def test_necisla(): # takhle se testuje vyhazování výjimek with pytest.raises(TypeError): Scitadlo.secti([], {}) - v terminálu ve správné složce: příkaz pytest
-
# Unittest # unittest vyžaduje specifické třídy a metody a dědění import unittest from scitadlo import Scitadlo class Testy(unittest.TestCase): def test_jedna_dva(self): self.assertEqual(Scitadlo.secti(1, 2), 3) def test_zaporne(self): self.assertEqual(Scitadlo.secti(1, -2), -1) def test_necisla(self): with self.assertRaises(TypeError): Scitadlo.secti([], {}) unittest.main()
grafika (tkinter)
-
tkinter (nebo jiný balíček pro grafiku, např. Kivy)
-
from tkinter import * hlavni_okno = Tk() hlavni_okno.mainloop()
-
from tkinter import * hlavni_okno = Tk() hlavni_okno.title("Pokusná apka") hlavni_okno.geometry('350x200') popisek = Label(hlavni_okno, text="Ahoj světe") popisek.pack() def pozdrav(): popisek.configure(text = 'Ahoj po kliknutí') print('Ahoj do konzole!') tlacitko_pozdrav = Button(hlavni_okno, text="Pozdrav!", command = pozdrav) tlacitko_pozdrav.pack() hlavni_okno.mainloop() -
class Karticka: def __init__(self, text): self.text = text self.tlacitko = Button(hlavni_okno, text = "KLIKNI", command = self.klik) self.tlacitko.pack() def klik(self): self.tlacitko.configure(text = self.text) -
popisek = Label(hlavni_okno, text="Ptakopysk") popisek.grid(row=0, column=1) # místo .pack()
-
-
úkol: naprogramujte pexeso
- kartičky, kliknutím otočím, zezadu něco (číslo/slovo/obrázek), kliknutím otočím zpátky
- pokud chci náhodně zamíchat list: random.shuffle(muj_list)
- volitelně: kontrolovat nalezení stejných kartiček, počítat počet tahů, automaticky otáčet kartičky, víceuživatelský režim.....
-
zdroje pro samostudium
- English tutorial
- český tutoriál
- nějaké moje zdrojáky: prvni karticky grid pexeso
Pokyny
-
doporučený editor: Visual Studio Code (ale používejte cokoliv chcete)
- tutoriál například zde: https://www.youtube.com/watch?v=WPqXP_kLzpo
- nějaké intro například zde: https://code.visualstudio.com/docs/python/python-tutorial
- účast je nepovinná (ale doporučená) -- pokud zvládnete snadno dělat domácí úkoly i bez účasti na cvičení, asi Vaše účast na cvičení není nutná
- můžete používat i vlastní notebook
Požadavky na zápočet
- domácí úkoly: aspoň 80% bodů
-
zápočtový test: aspoň 100% bodů
-
namísto posledního cvičení: 2.1.2023 16:30 N8 (sorry, prostě to tak vyšlo)
- pokud neuspějete napoprvé, máte nárok na opravné pokusy (minimálně 2)
-
termíny dalších pokusů domluvíme po testu
- druhý termín: 9.1.2023 16:30 N8
- třetí termín: bude vyhlášen
- možná další termín: buď 1.2.2023 14:30 nebo 3.2.2023 12:30 (upřesním)
- případně poslední termín v ZS: asi 6.2.2023 14:30 nebo 9.2.2023 14:30 (upřesním)
-
75 minut + minuta za každý bod navíc za domácí úkoly
- minimum bodů za úkoly je 80, pokud např. máte 99 bodů za úkoly, tak máte +19 minut na test
-
v Recodexu; ale musíte to řešit fyzicky v učebně
- rozsah obdobný domácímu úkolu
- nutné splnit na 100%
- povoleny libovolné zdroje kromě řešení zadané úlohy a aktivní komunikace (tj. můžete googlit, můžete koukat do slajdů, do svých poznámek, do řešení jiných úloh... ale nesmíte komunikovat s nikým)
- na začátku kontrola totožnosti (přineste si ISIC)
-
namísto posledního cvičení: 2.1.2023 16:30 N8 (sorry, prostě to tak vyšlo)
-
zápočtový program
- zadání dohodnout do 15.12.
- odevzdání doporučeno do konce zimního zkouškového, maximálně do konce března
- nutnost osobního předvedení (fyzicky nebo přes Zoom)
Domácí úkoly
- https://recodex.mff.cuni.cz/
- návod k Recodexu: https://github.com/ReCodEx/wiki/wiki/User-documentation
- každý týden nové domácí úkoly
- deadline 8 dnů od zadání (zadání v pondělí na cvičení, dedlajn následující týden v úterý 23:59)
Zápočtové programy

-
Jedním z požadavků na zápočet je, aby každý z vás samostatně stvořil větší prográmek, který bude něco dělat.
- Zadání si v tomto případě vymýšlíte sami, může to být úplně cokoliv
- Mělo by to být něco většího než běžný domácí úkol, tak zhruba na úrovni tří domácích úkolů v jednom.
- Můžete využívat libovolné existující knihovny a nástroje, ale musíte tam i nějakou podstatnou část naprogramovat sami.
-
Téma je nutné se mnou předem dohodnout
-
do 15.12. v SISu navrhněte téma (klidně i dřív)
-
modul Studijní mezivýsledky

- pole "zápočťák stručně": popište, co chcete dělat (max. 50 znaků)
- pole "zápočťák podrobně": podrobně popište, co chcete dělat (3 až 10 vět)
-
modul Studijní mezivýsledky
-
jakmile tam něco vyplníte, SIS mi pošle mail a já na to v dohledné době kouknu
- pokud mi zadání bude připadat dobré, tak ho rovnou v SISu schválím (pokud to máte povolené, SIS vám o tom pošle mail)
- pokud mi zadání nebude připadat dobré, napíšu vám mail a doladíme to
-
téma si pokud možno vymyslete sami
- to co si vymyslíte sami se vám nejlíp bude líp dělat a bude vás to víc bavit
- pokud máte vágní nápad ale nevíte jak z toho udělat splnitelné zadání, popište mi to do mailu a já něco navrhnu
-
Holan má na webu hezky zpracované návrhy na témata
- https://ksvi.mff.cuni.cz/~holan/zap_zs_2019-20_python.txt
- berte to jako inspiraci, ideální je když si zadání vymyslíte sami
-
moje nehezky zpracované návrhy
- https://docs.google.com/document/d/1E9s7KB46sPQ0ZN6XVg9XFTsCjIurB1UjyTfg4Y1RnvY/edit
- jsou to návrhy primárně na bakalářky a diplomky
- takže pro zápočťák je potřeba vybrat nějaké jednodušší téma
- anebo zpracovat jen část nějakého většího tématu
- některá témata se na zápočťák absolutně nehodí
- berte to jako inspiraci, ideální je když si zadání vymyslíte sami
-
do 15.12. v SISu navrhněte téma (klidně i dřív)
-
Na zápočťáku začněte ve vlastní zájmu dělat co nejdříve
- zkušenost ukazuje, že když si myslíte, že to budete mít za týden, bude to trvat spíš asi tak měsíc
- je matfyzáckým zvykem na zápoč'ťáku dělat přes Vánoční prázdniny; ale během zkouškového na to taky asi budete mít nějaký čas
-
Zápočťák vypracujte do konce března
- ale pokud chcete zápočet z Programování do konce února (pro účely kontroly studijních povinností), vypracujte ho nejpozději do konce zkouškového (tj. do 13.2.)
- pokud zdrojáky zabalené v ZIPu projdou omezením na velikost v SISu, nahrajte je přímo do SISu ("zápočťák: kód (ZIP archiv)"); jinak zašlete e-mailem
-
Součástí zápočťáku je také dokumentace

- ve zdrojových kódech používejte komentáře vysvětlující co která část kódu dělá (jak komentáře nemají vypadat viz obrázek)
- pokud to dává smysl, přiložte i testovací vstupní data
-
v SISu vyplňte položku "zápočťák: dokumentace"
- můžete dokumentaci buď vepsat přímo v SISu ("zápočťák: dokumentace (text)")
- anebo nahrát do SISu jako soubor ("zápočťák: dokumentace (soubor)")
-
dokumentace by měla obsahovat
- popis řešené úlohy
- popis vstupů, výstupů, ovládání
- popis principu řešení
- popis použitých datových struktur a algoritmů
- Vaše vlastní zhodnocení kvality Vašeho řešení (pokuste se být upřímní)
- psaní dokumentace je dobrým cvičením například na v budoucnu vás čekající psaní bakalářské práce
- dokumentace by měla zachycovat vše co je důležité či zajímavé (na co jste třeba hrdí)
- dokumentace by se měla držet na vyšší úrovní abstrakce (popisovat některé důležité objekty a třídy užívané v programu je rozumné, popisovat každou jednotlivou proměnnou rozumné není
- nějaké tipy jak psát dokumentaci: https://ksvi.mff.cuni.cz/~kryl/dokumentace.htm
-
Až budete mít zápočťák hotový, napište mi mail a domluvíme se na termínu osobního předvedení
- sejdeme se v labu
- vy mi program předvedete
- já si ho taky vyzkouším
- podívám se na zdrojový kód
- pokud budu spokojen, máte tímto zápočťák splněn
- pokud ne, dám vám program dopracovat
Další informace
-
kromě domácích úloh vřele doporučuji následující sbírku zejména jednodušších programovacích úloh: https://codingbat.com/python
- podobně jako v Recodexu je kód automaticky vyhodnocen
- narozdíl od Recodexu i vidíte správné i chybné vstupy i výstupy
- nebo například zde: